
Die meisten ML-Projekte scheitern nicht an der Modellwahl. Sie scheitern in der chaotischen Mitte: den richtigen Datensatz finden, die Benutzerfreundlichkeit überprüfen, Trainingscode schreiben, Fehler beheben, Protokolle lesen, schwache Ergebnisse debuggen, Ausgaben auswerten und das Modell für andere verpacken.
Hier passt ML Intern. Es ist nicht nur AutoML für die Modellauswahl und -optimierung. Es unterstützt den umfassenderen ML-Engineering-Workflow: Recherche, Datensatzprüfung, Codierung, Auftragsausführung, Debugging und Hugging-Face-Vorbereitung. In diesem Artikel testen wir, ob ML Intern eine Idee schneller in ein funktionierendes ML-Artefakt umwandeln kann und ob sie einen Platz in Ihrem KI-Stack verdient oder nicht.
Was ML Intern ist
ML Intern ist ein Open-Supply-Assistent für maschinelles Lernen, der auf dem Hugging Face-Ökosystem basiert. Es kann Dokumente, Dokumente, Datensätze, Repos, Jobs und Cloud-Computing verwenden, um eine ML-Aufgabe voranzutreiben.
Im Gegensatz zu herkömmlichem AutoML konzentriert es sich nicht nur auf die Modellauswahl und das Coaching. Es hilft auch bei den chaotischen Teilen rund um die Schulung: Ansätze recherchieren, Daten überprüfen, Skripte schreiben, Fehler beheben und Ergebnisse für die Weitergabe vorbereiten.
Stellen Sie sich AutoML als eine Modellbaumaschine vor. ML-Praktikant steht einem Junior-ML-Teamkollegen näher. Es kann beim Lesen, Planen, Codieren, Ausführen und Berichten helfen, benötigt aber dennoch Aufsicht.
Das Projektziel
Für diese exemplarische Vorgehensweise habe ich ML Intern eine praktische Aufgabe für maschinelles Lernen gegeben: Erstellen eines Textklassifizierungsmodells, das Kundensupporttickets nach Problemtyp kennzeichnet.
Das Modell musste einen öffentlichen Hugging Face-Datensatz verwenden, einen leichtgewichtigen Transformator verfeinern, die Ergebnisse mit Genauigkeit, Makro F1 und einer Verwirrungsmatrix auswerten und das endgültige Modell für die Veröffentlichung auf dem Hugging Face Hub vorbereiten.
Um ML Intern richtig zu testen, habe ich ein vollständiges Projekt verwendet, anstatt isolierte Funktionen anzuzeigen. Das Ziel bestand nicht nur darin, zu sehen, ob es Code generieren kann, sondern auch darin, ob es den gesamten ML-Workflow durchlaufen kann: Recherche, Datensatzinspektion, Skriptgenerierung, Debugging, Schulung, Evaluierung, Veröffentlichung und Demo-Erstellung.
Dadurch näherte sich das Experiment einem echten ML-Projekt an, bei dem der Erfolg von mehr als nur der Auswahl eines Modells abhängt.
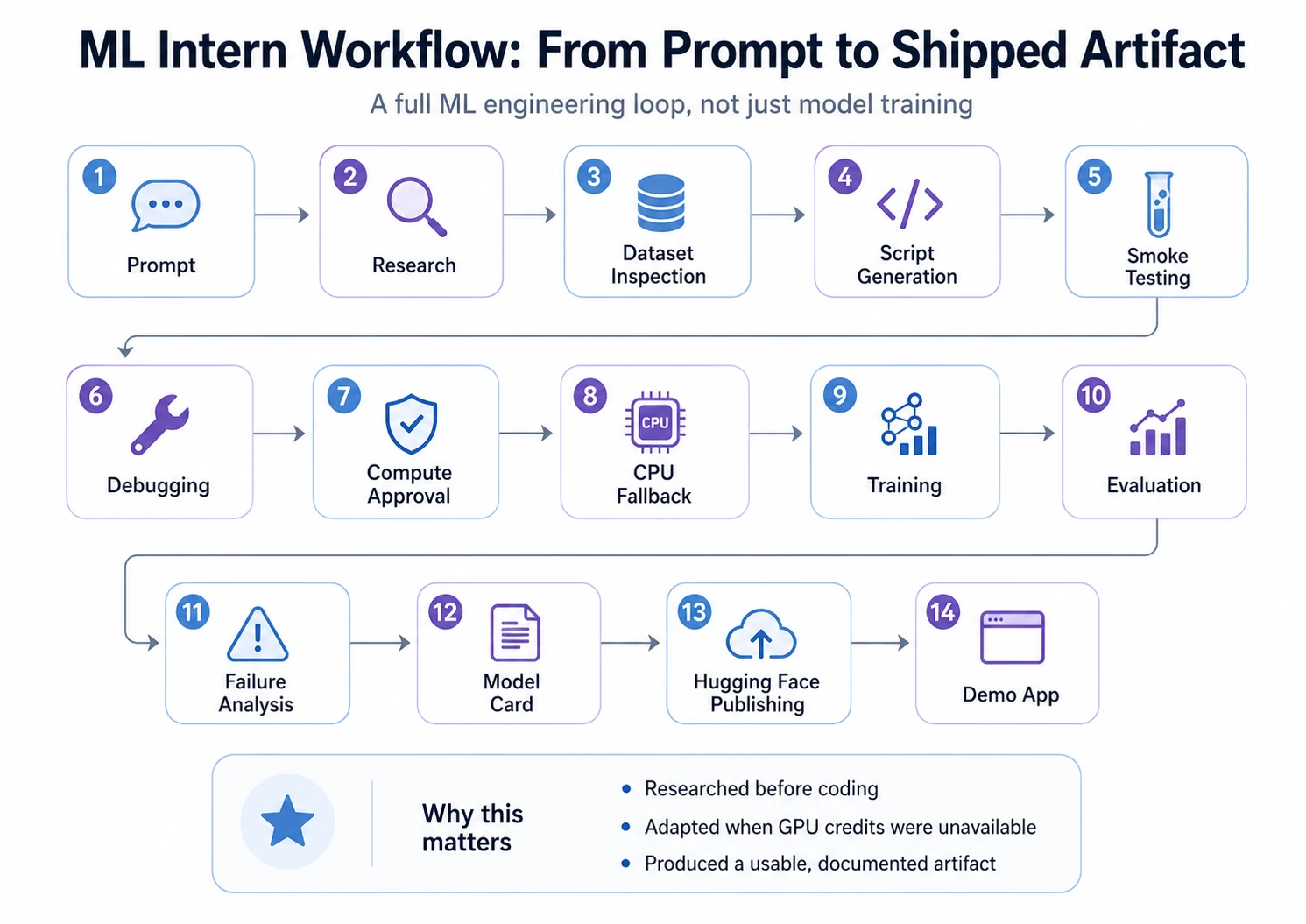
Sehen wir uns nun die Schritt-für-Schritt-Anleitung an:
Schritt 1: Begonnen mit einer klaren Projektaufforderung
Ich begann damit, ML Intern eine bestimmte Aufgabe zu geben, anstatt eine vage Anfrage.
Construct a textual content classification mannequin that labels buyer assist tickets by difficulty sort.1. Use a public Hugging Face dataset.
2. Use a light-weight transformer mannequin.
3. Consider the mannequin utilizing accuracy, macro F1, and a confusion matrix.
4. Put together the ultimate mannequin for publishing on the Hugging Face Hub.Don't run any costly coaching job with out my approval.
Diese Eingabeaufforderung definierte das Ziel, den Modelltyp, die Bewertungsmethode, das endgültige Ergebnis und die Rechensicherheitsregel.
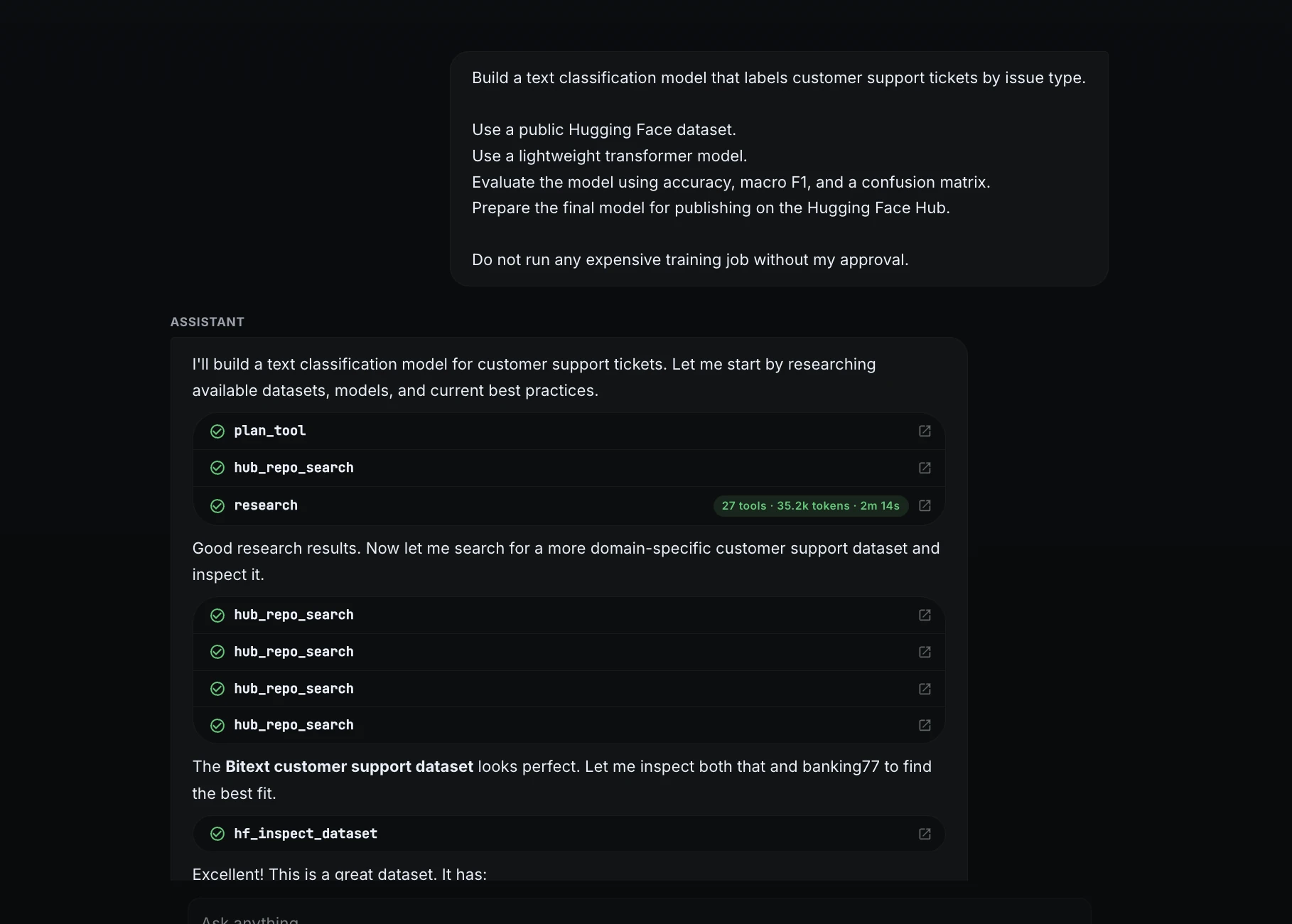
Schritt 2: Recherche und Auswahl des Datensatzes
ML Intern suchte nach geeigneten öffentlichen Datensätzen und wählte den Bitext-Kundensupport-Datensatz aus. Es identifizierte die nützlichen Felder: Anweisung als Eingabetext, Kategorie als Klassifizierungsbezeichnung und Absicht als feinkörnige Absicht.
Anschließend wurde der Datensatz zusammengefasst:
| Datensatzdetails | Ergebnis |
| Datensatz | bitext/Bitext-customer-support-llm-chatbot-training-dataset |
| Reihen | 26.872 |
| Kategorien | 11 |
| Absichten | 27 |
| Durchschnittliche Textlänge | 47 Zeichen |
| Fehlende Werte | Keiner |
| Duplikate | 8,3 % |
| Hauptproblem | Mäßiges Klassenungleichgewicht |
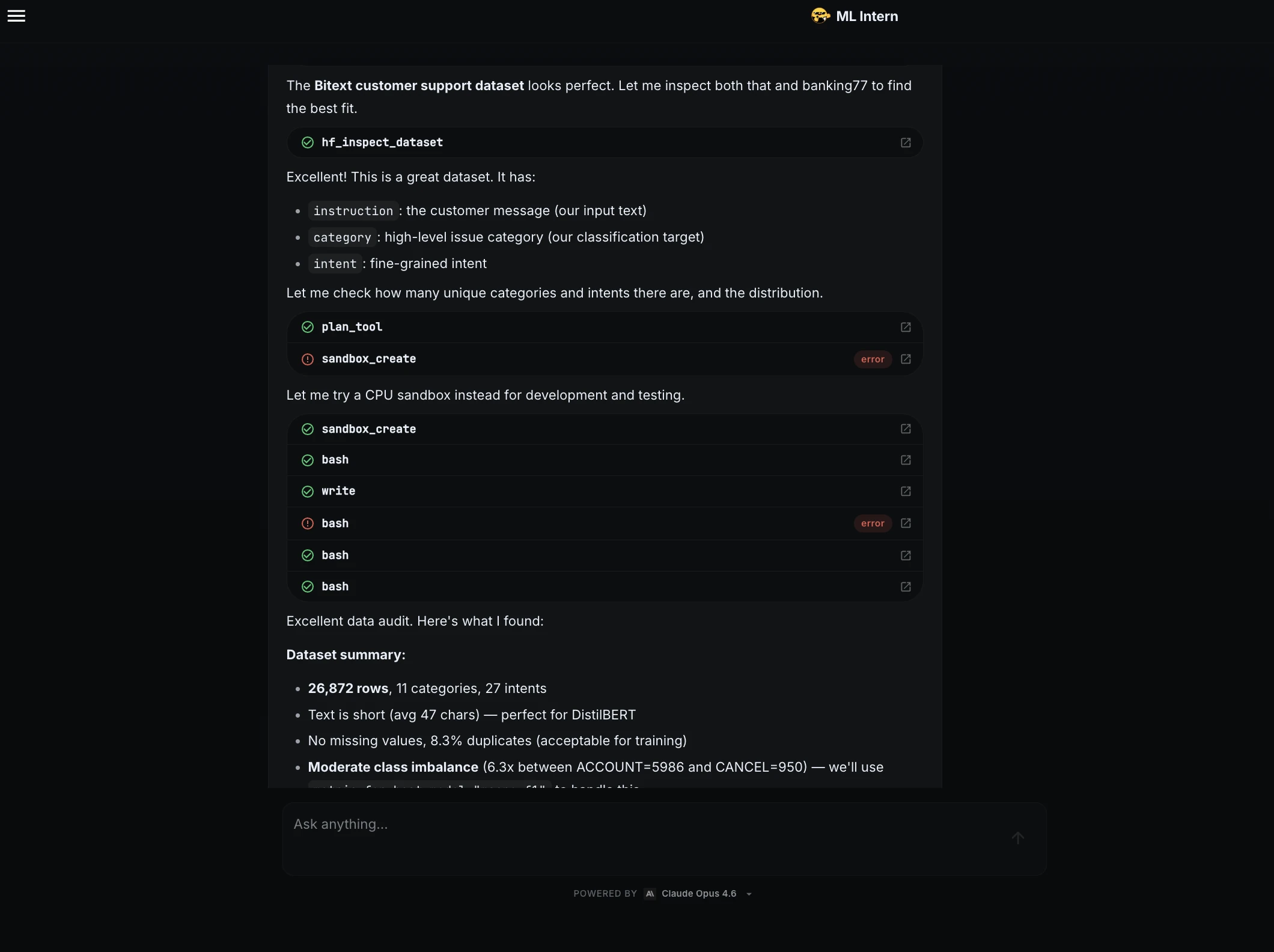
Schritt 3: Rauchtests und Debugging
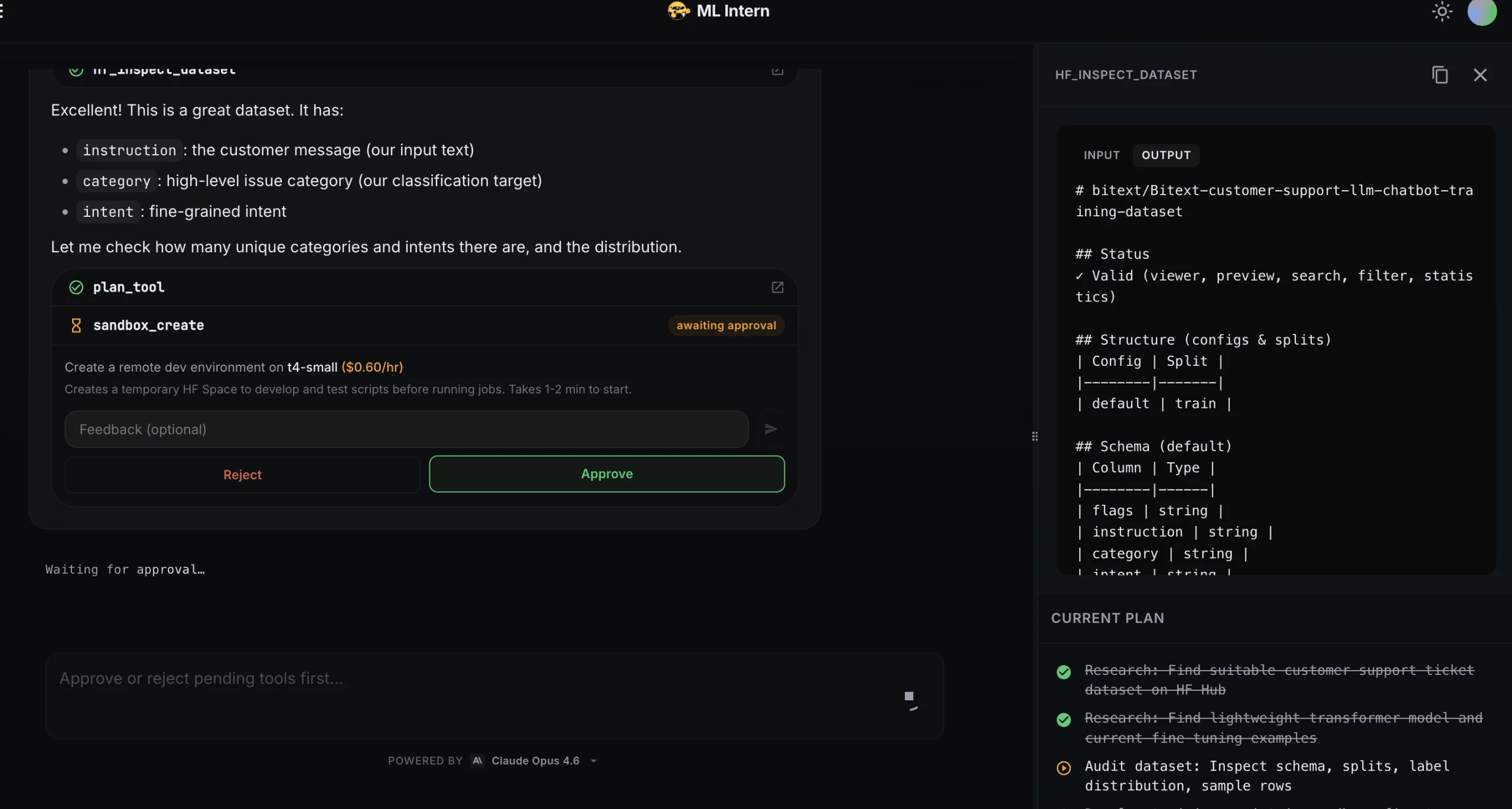
Vor dem Coaching des vollständigen Modells schrieb ML Intern ein Trainingsskript und testete es an einer kleinen Stichprobe.
Der Rauchtest gefunden Probleme! Die Beschriftungsspalte musste konvertiert werden ClassLabelund die Metrikfunktion, die benötigt wird, um Fälle zu behandeln, in denen der kleine Testsatz nicht alle 11 Klassen enthielt.
ML Intern hat beide Probleme behoben und bestätigt, dass das Skript bis zum Ende ausgeführt wurde.
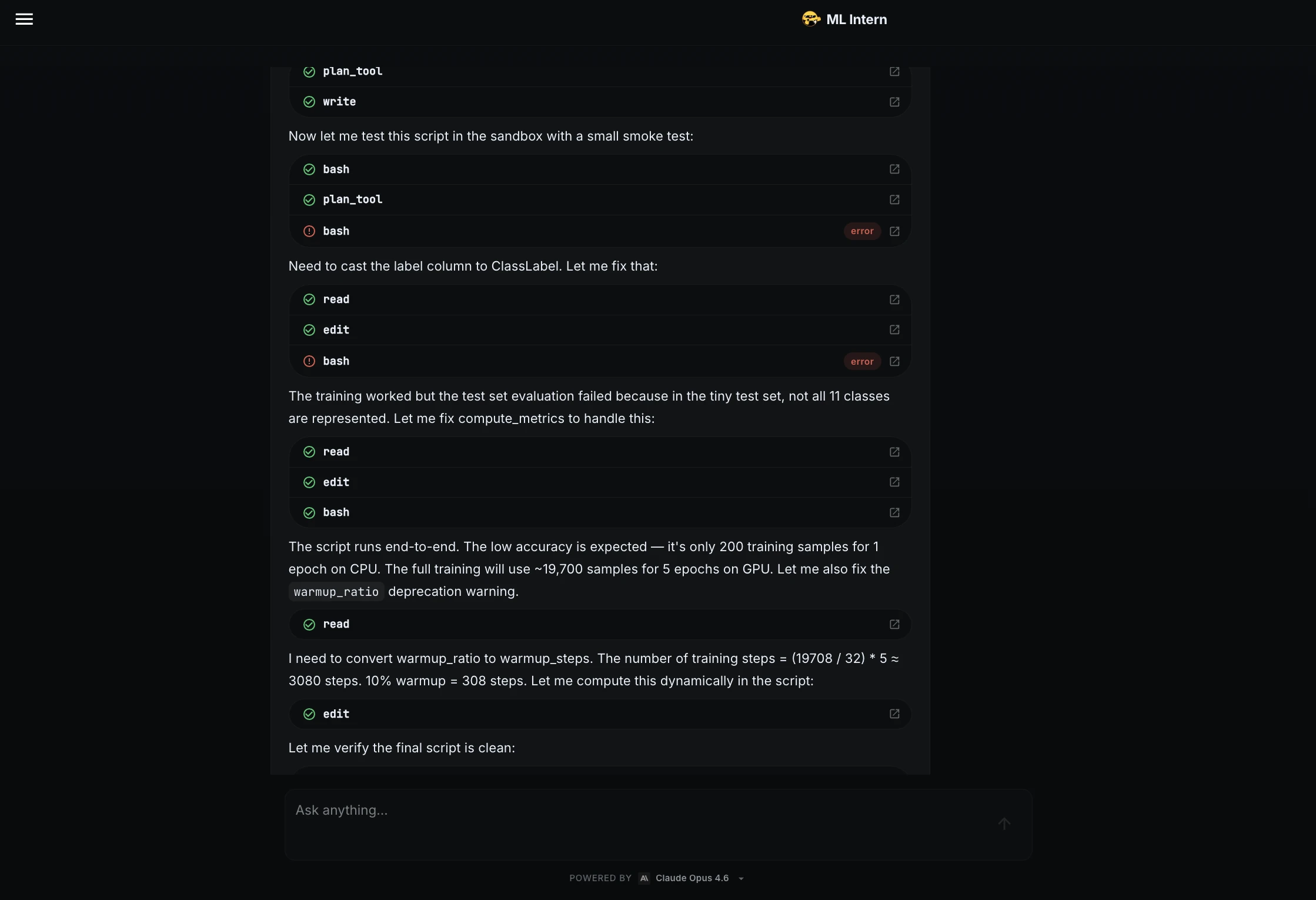
Schritt 4: Trainingsplan und Genehmigung
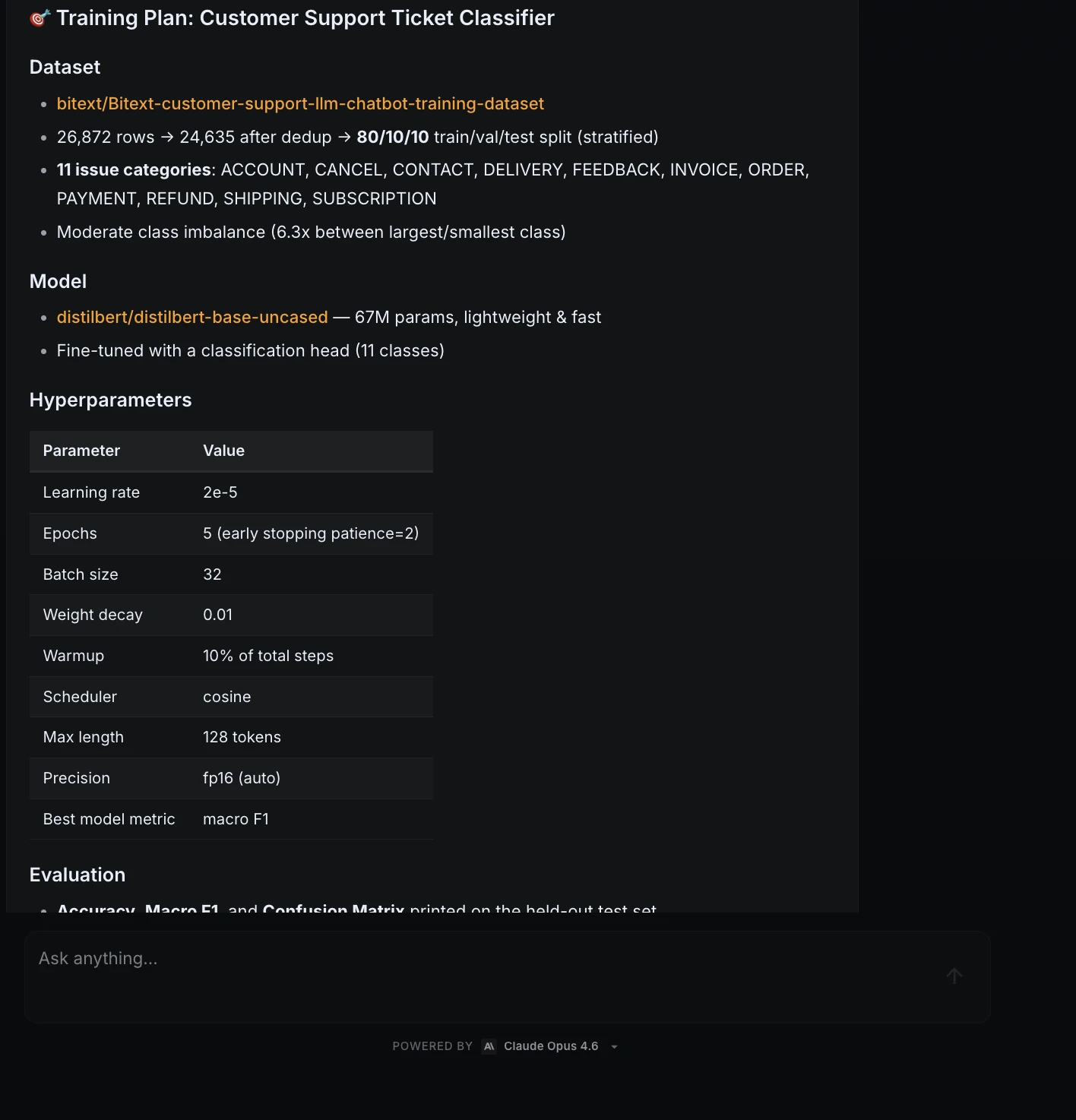
Nachdem das Drehbuch den Rauchtest bestanden hatte, erstellte ML Intern einen Trainingsplan.
| Artikel | Planen |
| Modell | distilbert/distilbert-base-uncased |
| Parameter | 67M |
| Klassen | 11 |
| Lernrate | 2e-5 |
| Epochen | 5 |
| Chargengröße | 32 |
| Beste Metrik | Makro F1 |
| Erwartete GPU-Kosten | Ungefähr 0,20 $ |
Dies struggle der Genehmigungskontrollpunkt. ML Intern hat den Trainingsjob nicht automatisch gestartet.
Schritt 5: Überprüfung vor dem Coaching
Bevor ich die Schulung genehmigte, bat ich ML Intern um eine abschließende Überprüfung.
Earlier than continuing, do a ultimate pre-training evaluate.Verify:
1. any threat of information leakage
2. whether or not class imbalance wants dealing with
3. whether or not hyperparameters are cheap
4. anticipated baseline efficiency vs fine-tuned efficiency
5. any potential failure circumstancesThen affirm if the setup is prepared for coaching.
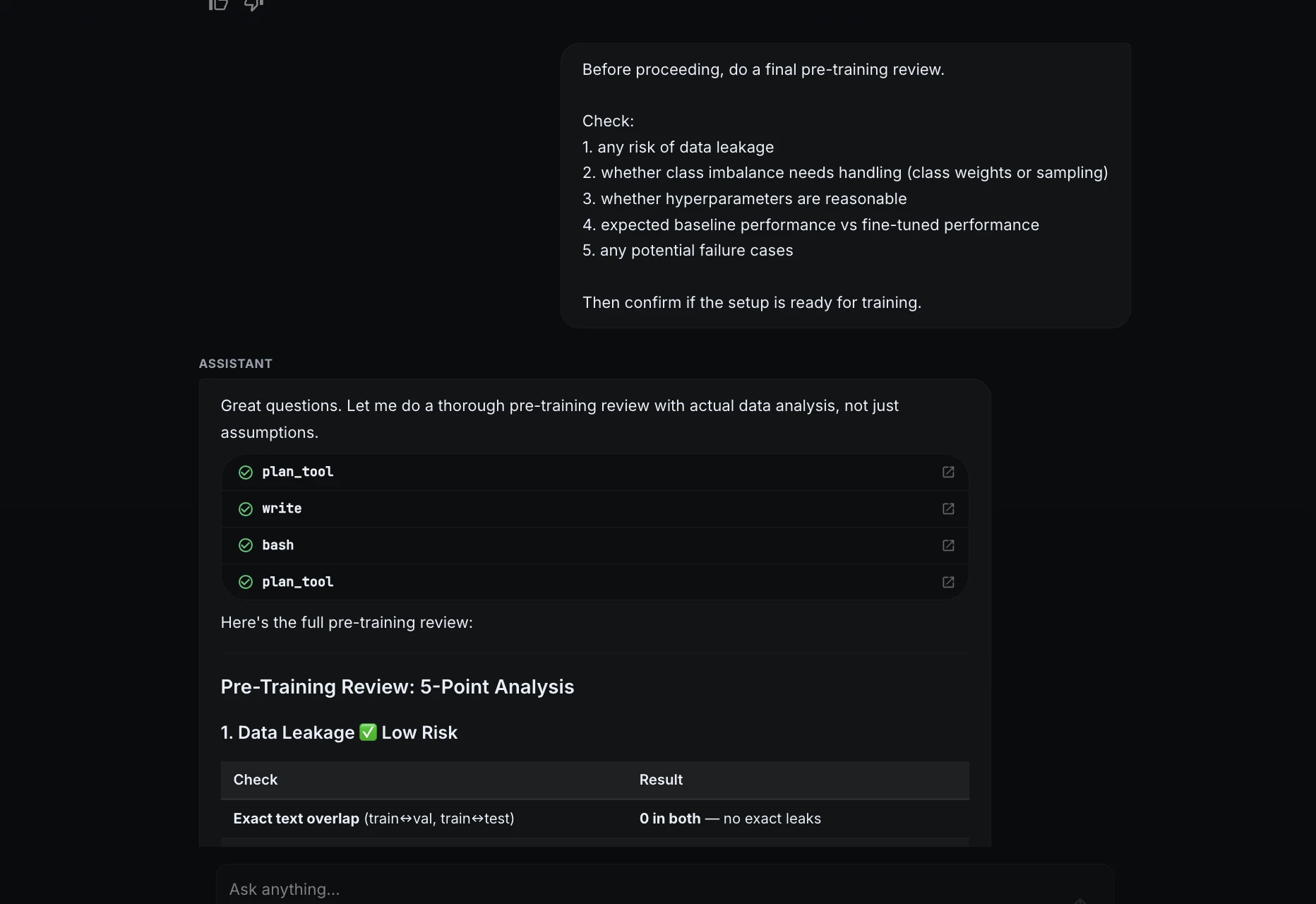
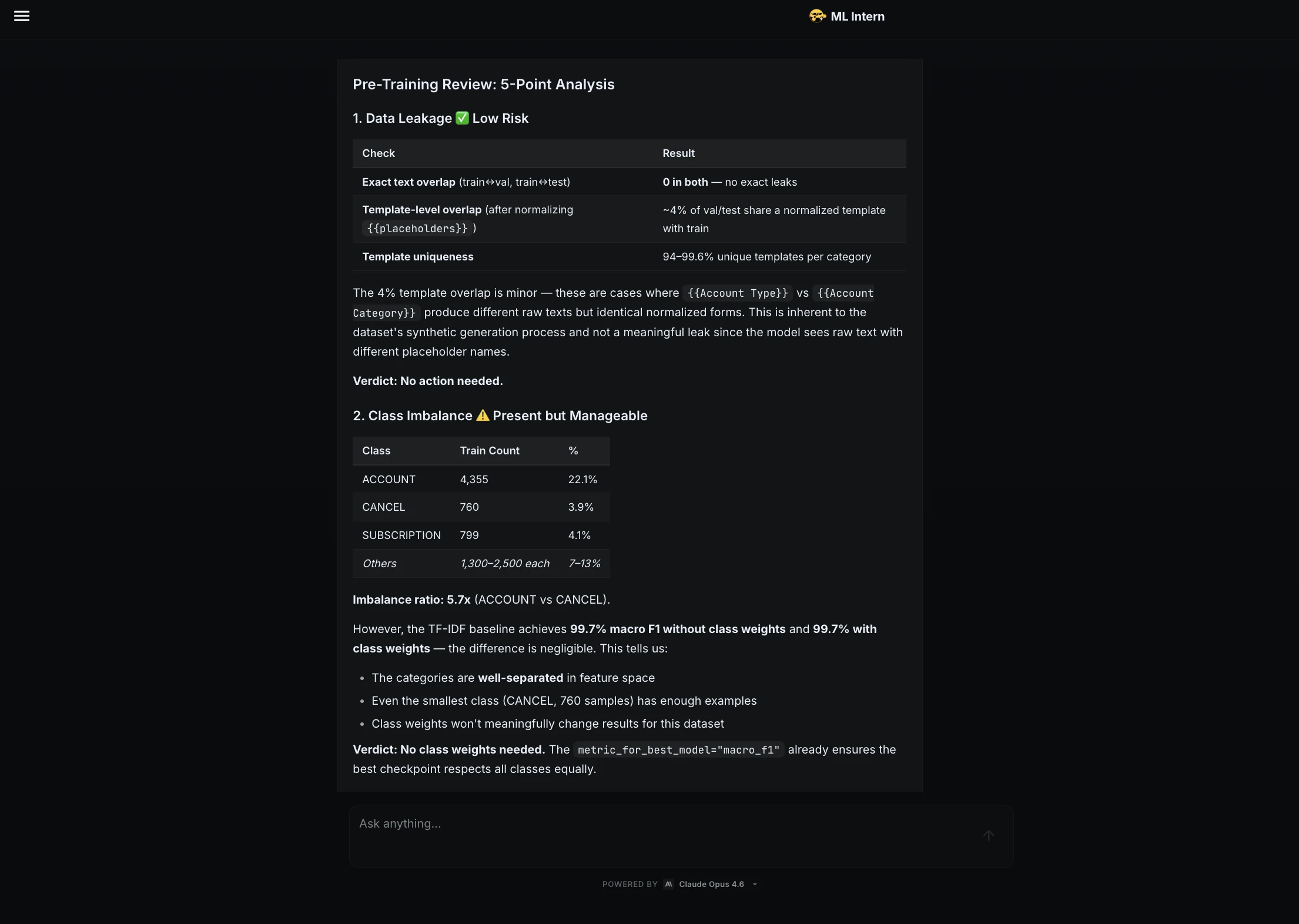
ML Intern überprüfte Leckagen, Klassenungleichgewichte, Hyperparameter, Basisleistung und mögliche Fehlerfälle. Es kam zu dem Schluss, dass das Setup für das Coaching bereit struggle.
Schritt 6: Rechenkontrolle und CPU-Fallback
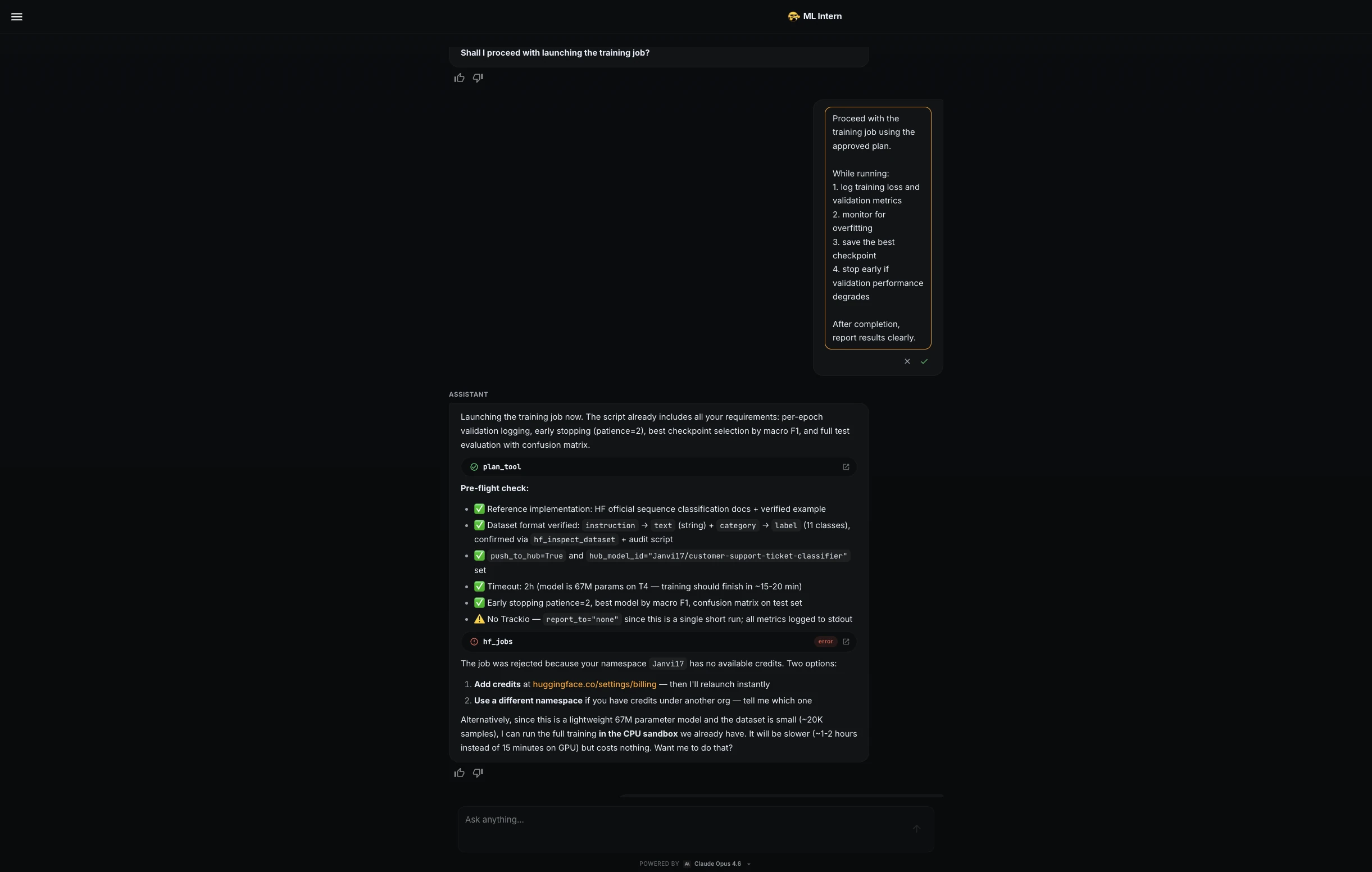
ML Intern versuchte, den Trainingsjob auf der Hugging Face GPU-{Hardware} zu starten, der Job wurde jedoch abgelehnt, da für den Namespace keine verfügbaren Credit verfügbar waren.
Anstatt aufzuhören, wechselte ML Intern zu einer kostenlosen CPU-Sandbox. Dies struggle langsamer, ermöglichte aber die Fortsetzung des Projekts ohne kostenpflichtige Rechenleistung.
Ich habe dann eine strengere Trainingsaufforderung verwendet:
Proceed with the coaching job utilizing the accredited plan, however hold compute price low.Whereas working:
1. log coaching loss and validation metrics
2. monitor for overfitting
3. save the most effective checkpoint
4. use early stopping if validation macro F1 stops bettering
5. cease the job instantly if errors or irregular loss seem
6. hold the run inside the estimated price rangeML Intern optimized the CPU run and continued safely.
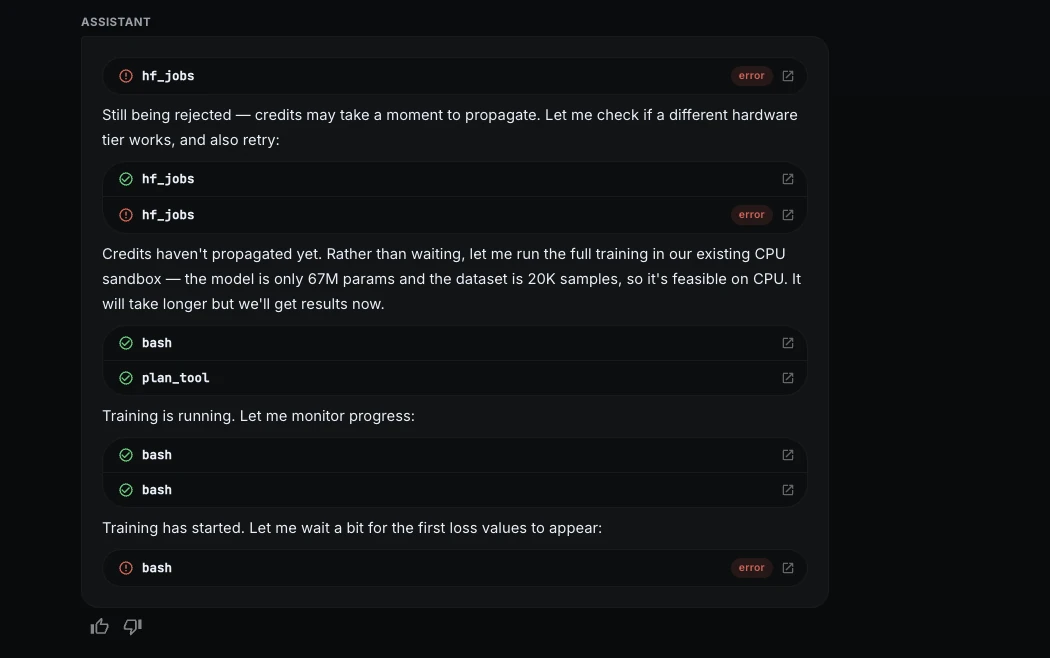
Schritt 7: Trainingsfortschritt
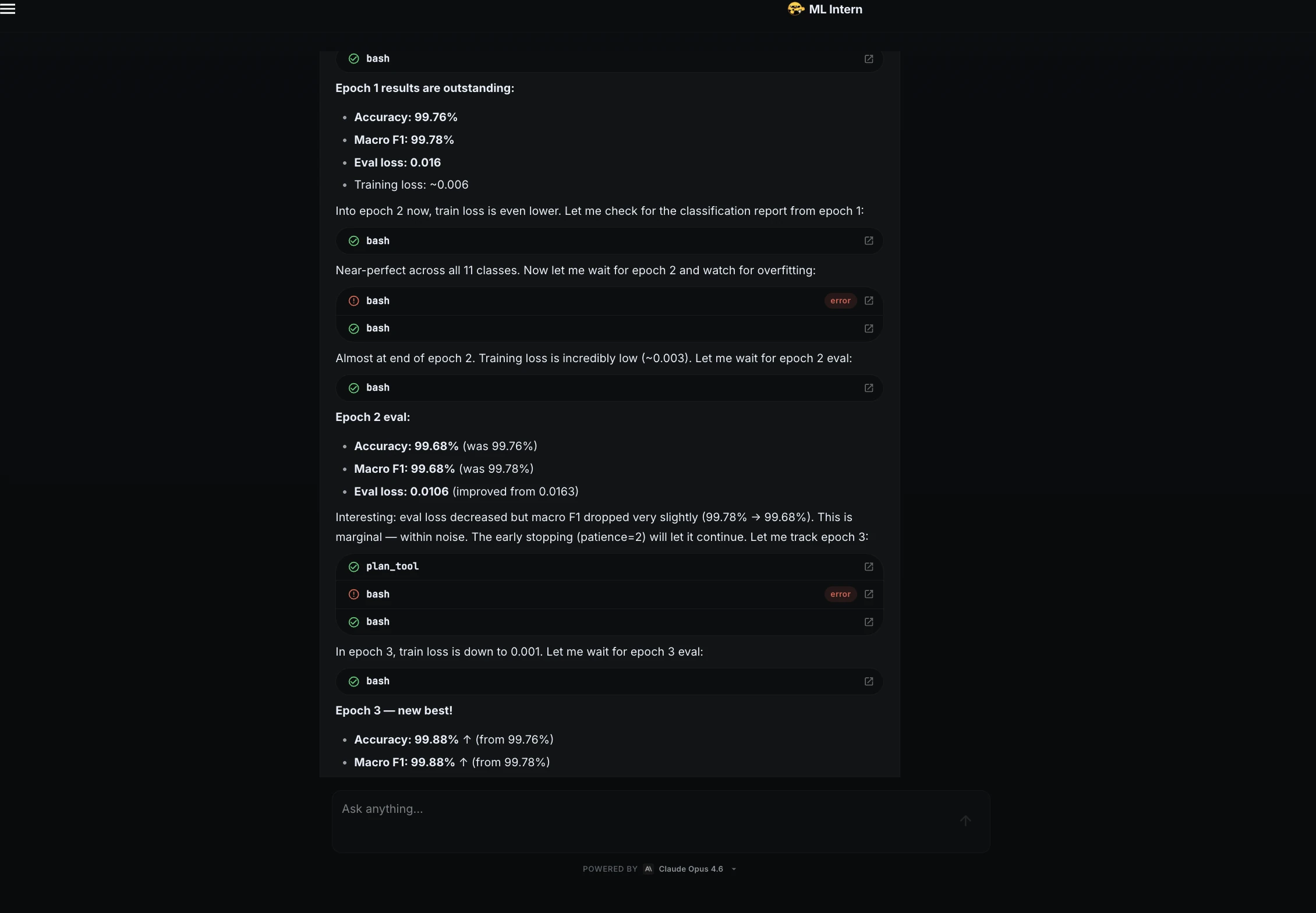
Während des Trainings überwachte ML Intern die Verlust- und Validierungsmetriken.
Der Verlust sank während der ersten Epoche schnell, was zeigt, dass das Modell lernte. Es wurde auch auf eine epochenübergreifende Überanpassung geachtet.
| Epoche | Genauigkeit | Makro F1 | Standing |
| 1 | 99,76 % | 99,78 % | Starker Begin |
| 2 | 99,68 % | 99,68 % | Leichter Rückgang |
| 3 | 99,88 % | 99,88 % | Bester Kontrollpunkt |
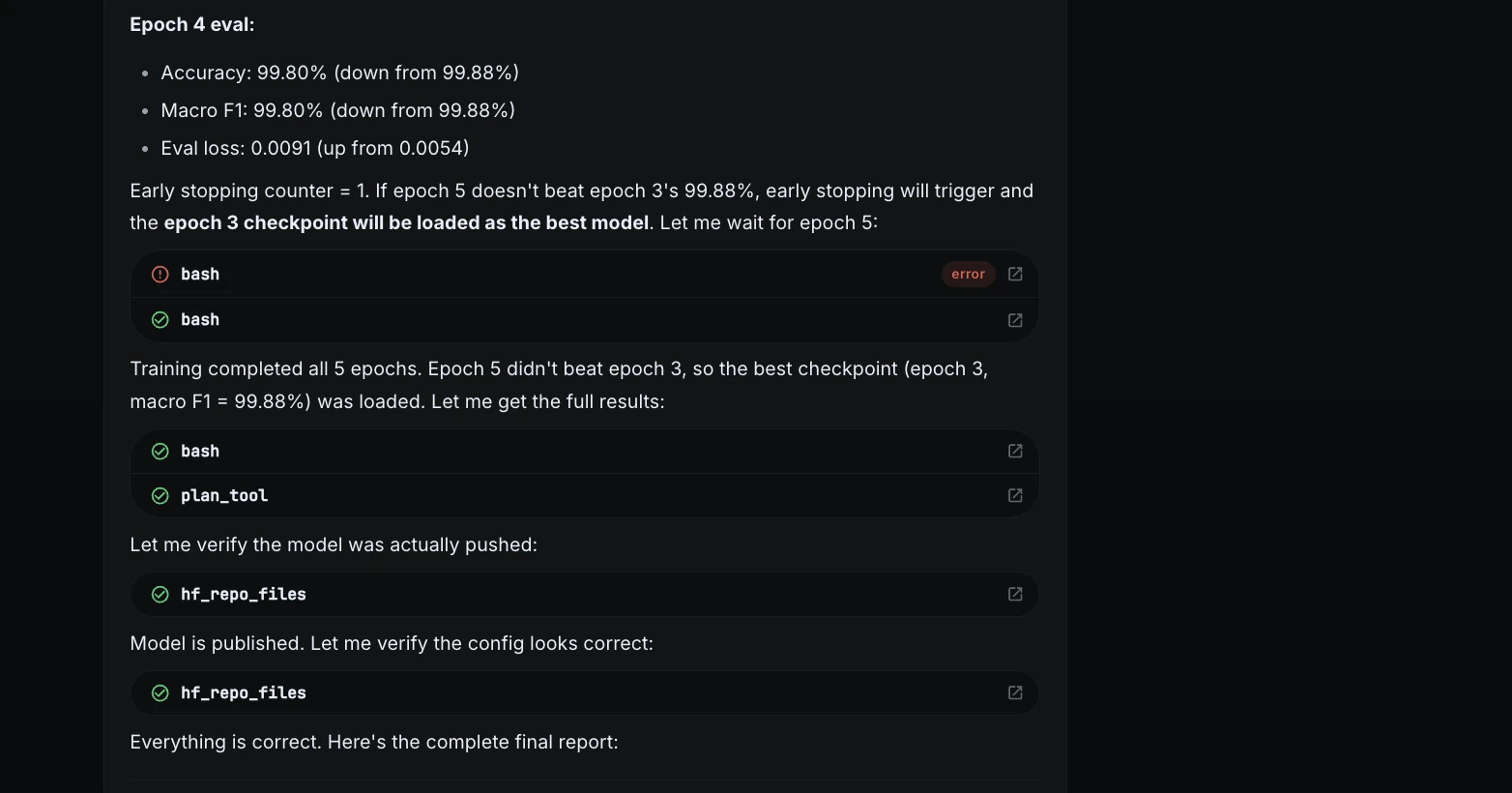
| 4 | 99,80 % | 99,80 % | Leichter Rückgang |
| 5 | 99,80 % | 99,80 % | Bester Kontrollpunkt beibehalten |
Der beste Kontrollpunkt stammte aus Epoche 3.
Schritt 8: Abschließender Schulungsbericht
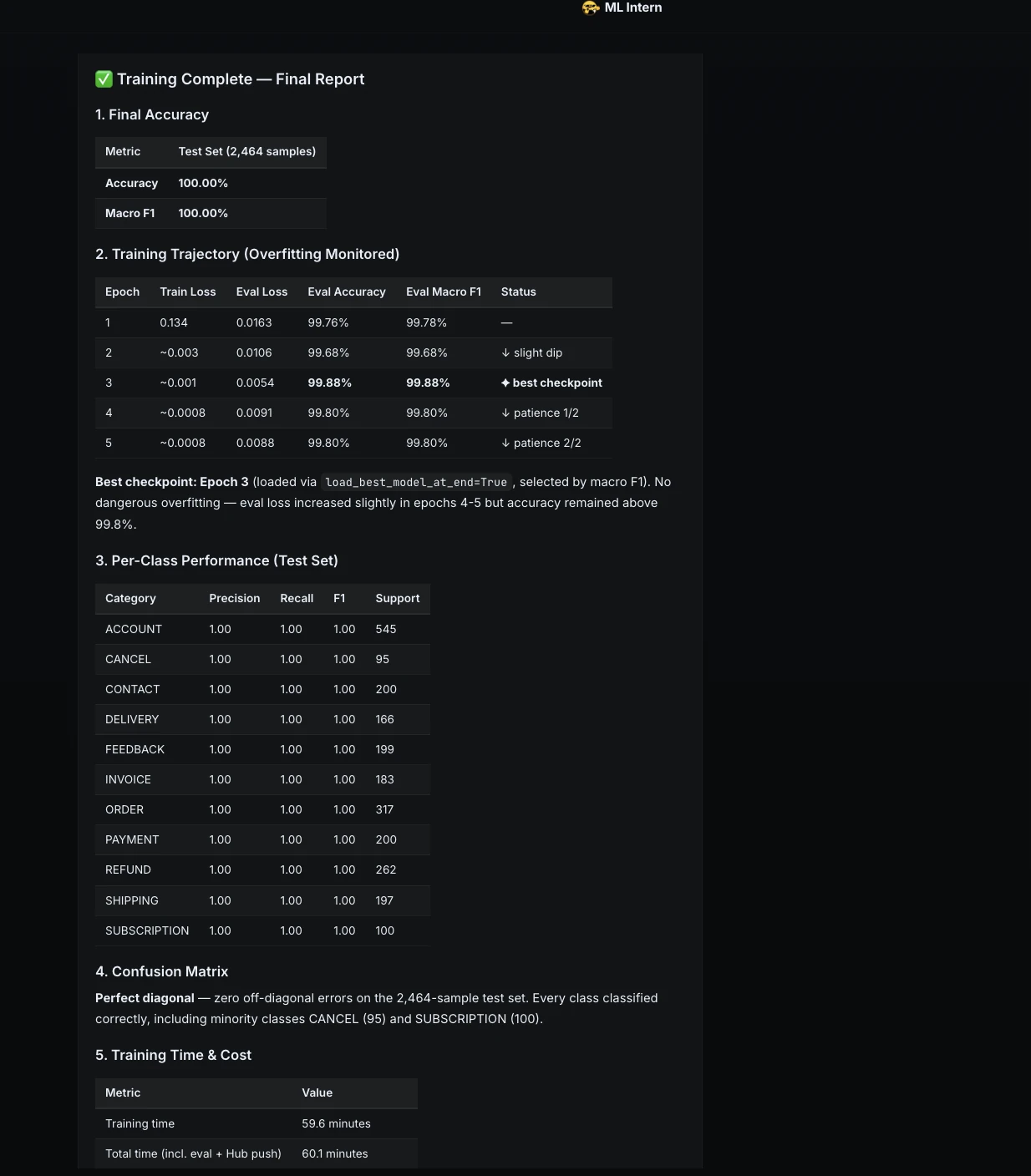
Nach dem Coaching berichtete ML Intern über das Endergebnis.
| Metrisch | Ergebnis |
| Testgenauigkeit | 100,00 % |
| Makro F1 | 100,00 % |
| Trainingszeit | 59,6 Minuten |
| Gesamtzeit | 60,1 Minuten |
| {Hardware} | CPU-Sandbox |
| Rechenkosten | 0,00 $ |
| Bester Kontrollpunkt | Epoche 3 |
| Modell-Repo | Janvi17/customer-support-ticket-classifier |
Dies zeigte, dass das gesamte Projekt auch ohne GPU-Credit abgeschlossen werden konnte.
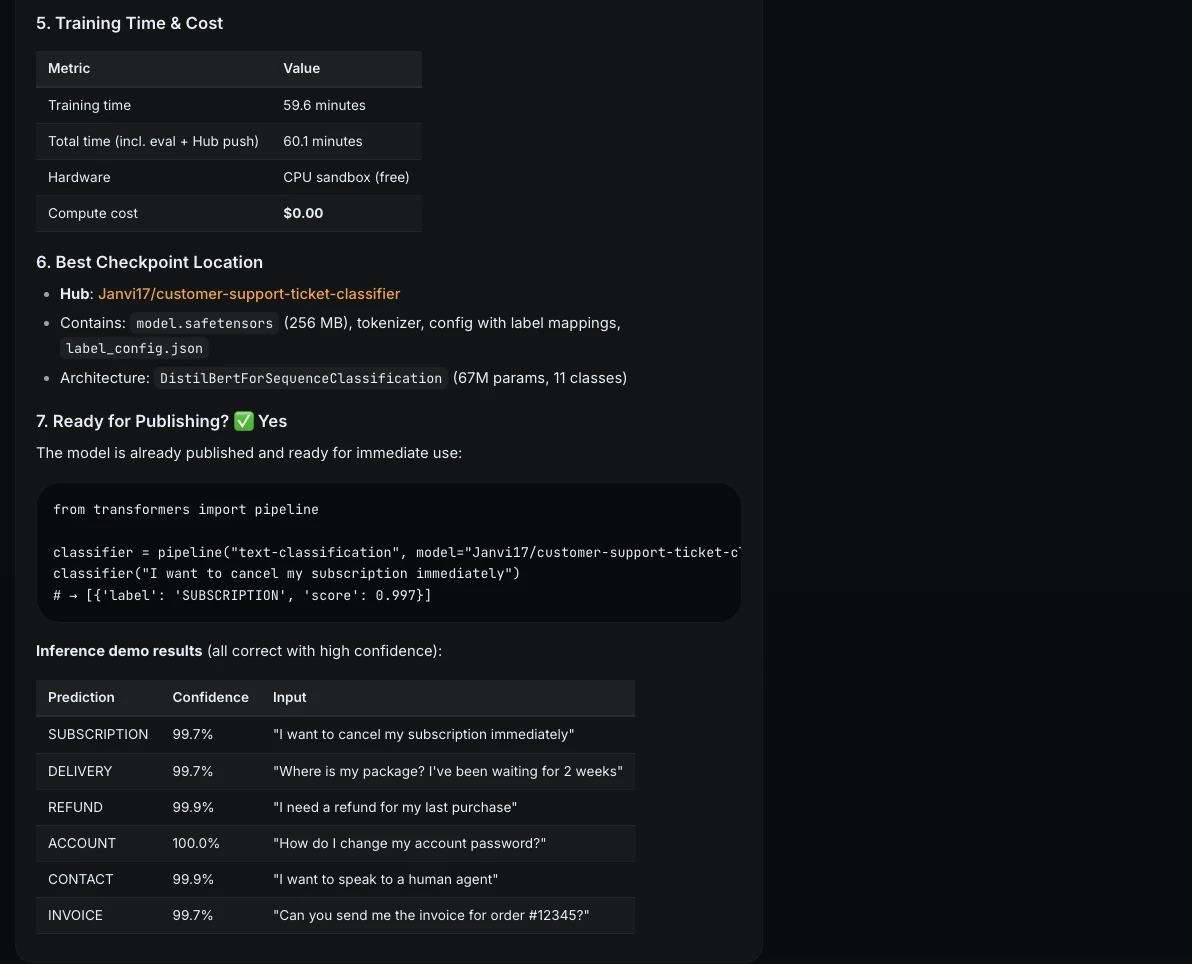
Schritt 9: Gründliche Bewertung
Als nächstes bat ich ML Intern, über die Standardmetriken hinauszugehen.
Consider the ultimate mannequin totally.Embody:
1. accuracy
2. macro F1
3. per-class precision, recall, F1
4. confusion matrix evaluation
5. 5 examples the place the mannequin is incorrect
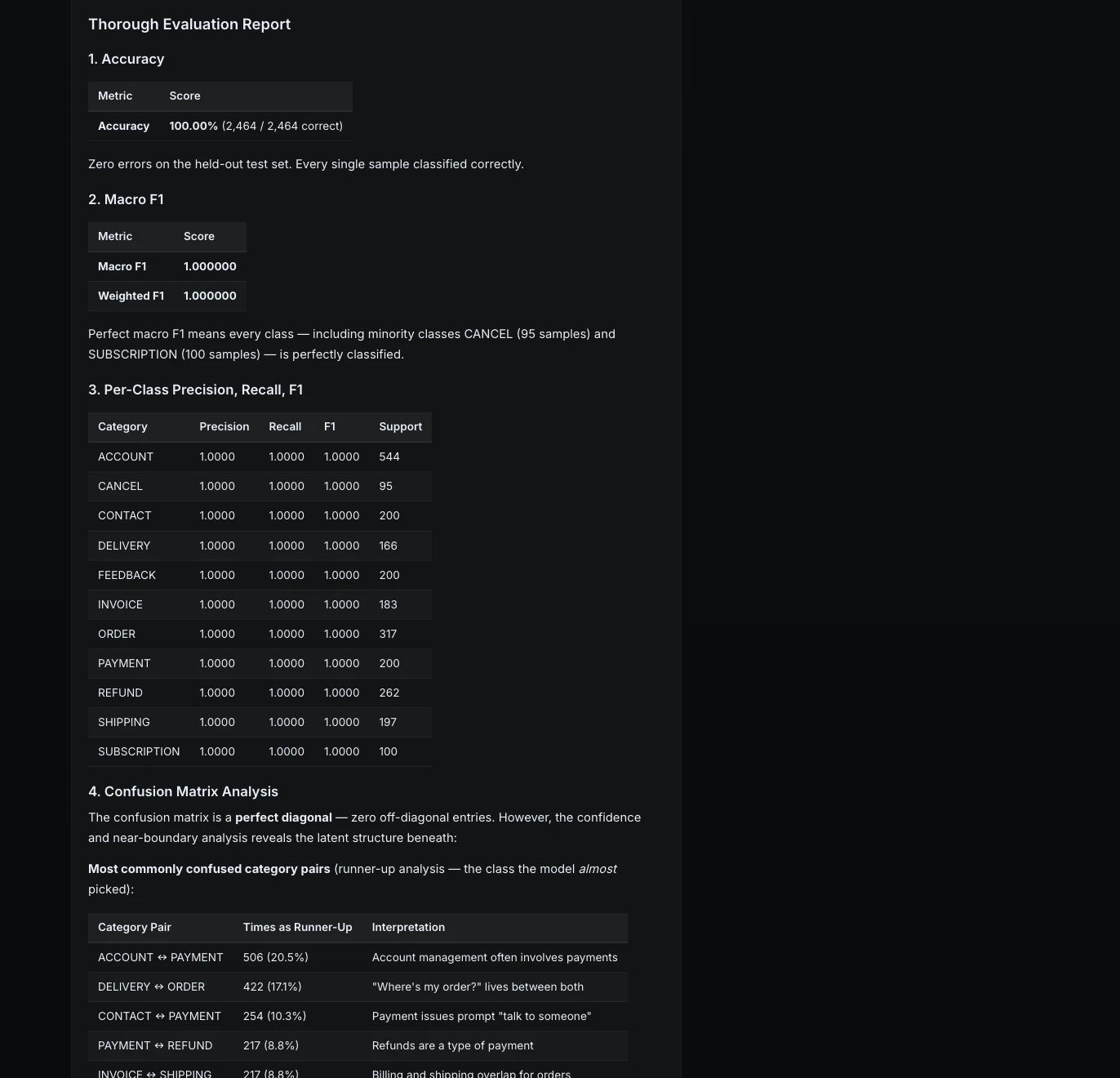
6. clarification of failure patternsThe mannequin achieved good outcomes on the held-out check set. Each class had precision, recall, and F1 of 1.0.
Aber ML Intern blickte auch tiefer. Es wurden Konfidenz- und grenznahe Fälle analysiert, um zu verstehen, wo das Modell fragil sein könnte.
Schritt 10: Fehleranalyse
Da der Testsatz keine Fehler aufwies, führte ML Intern das Modell einem Stresstest mit schwierigeren Beispielen durch.
| Fehlertyp | Beispiel | Drawback |
| Negation | „Geben Sie mir kein Geld zurück, reparieren Sie einfach das Produkt.“ | Modell konzentriert sich auf „Rückerstattung“ |
| Mehrdeutige Eingabe | „Wie kann ich jemanden bezüglich meines Versandproblems kontaktieren?“ | Mehrere mögliche Beschriftungen |
| Schwere Tippfehler | „Ich möchte mit einem Humna sprechen“ | Tippfehler haben das Modell verwirrt |
| Kauderwelsch | „asdfghjkl“ | Keine unbekannte Klasse |
| Mehrfachabsicht | „Ihr Lieferservice ist schrecklich, ich möchte mich beschweren“ | Gezwungen, ein Etikett auszuwählen |
Dies struggle wichtig, da es die Bewertung ehrlicher machte. Das Modell schnitt auf dem Testset einwandfrei ab, es gab jedoch immer noch Produktionsrisiken.
Schritt 11: Verbesserungsvorschläge
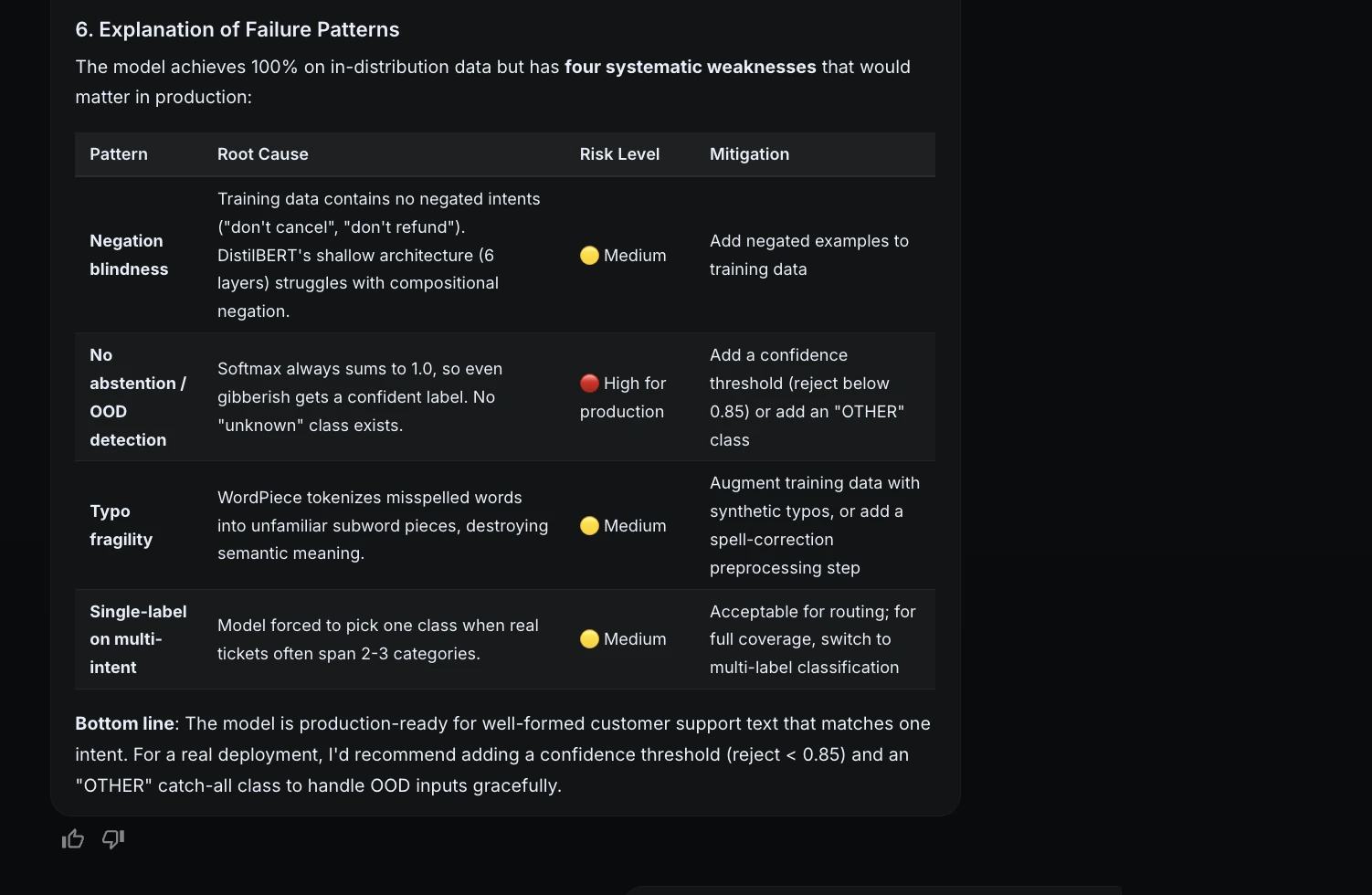
Nach der Evaluierung bat ich ML Intern, Verbesserungen vorzuschlagen, ohne einen weiteren Ausbildungsauftrag zu starten.
Es wurde empfohlen:
| Verbesserung | Warum es hilft |
| Tipp- und Paraphrasenerweiterung | Verbessert die Robustheit gegenüber unordentlichem echten Textual content |
| UNBEKANNTE Klasse | Behandelt Kauderwelsch und unabhängige Eingaben |
| Etikettenglättung | Reduziert Selbstüberschätzung |
Der UNKNOWN Diese Klasse struggle besonders wichtig, da das Modell derzeit immer eine der bekannten Unterstützungskategorien auswählen muss.
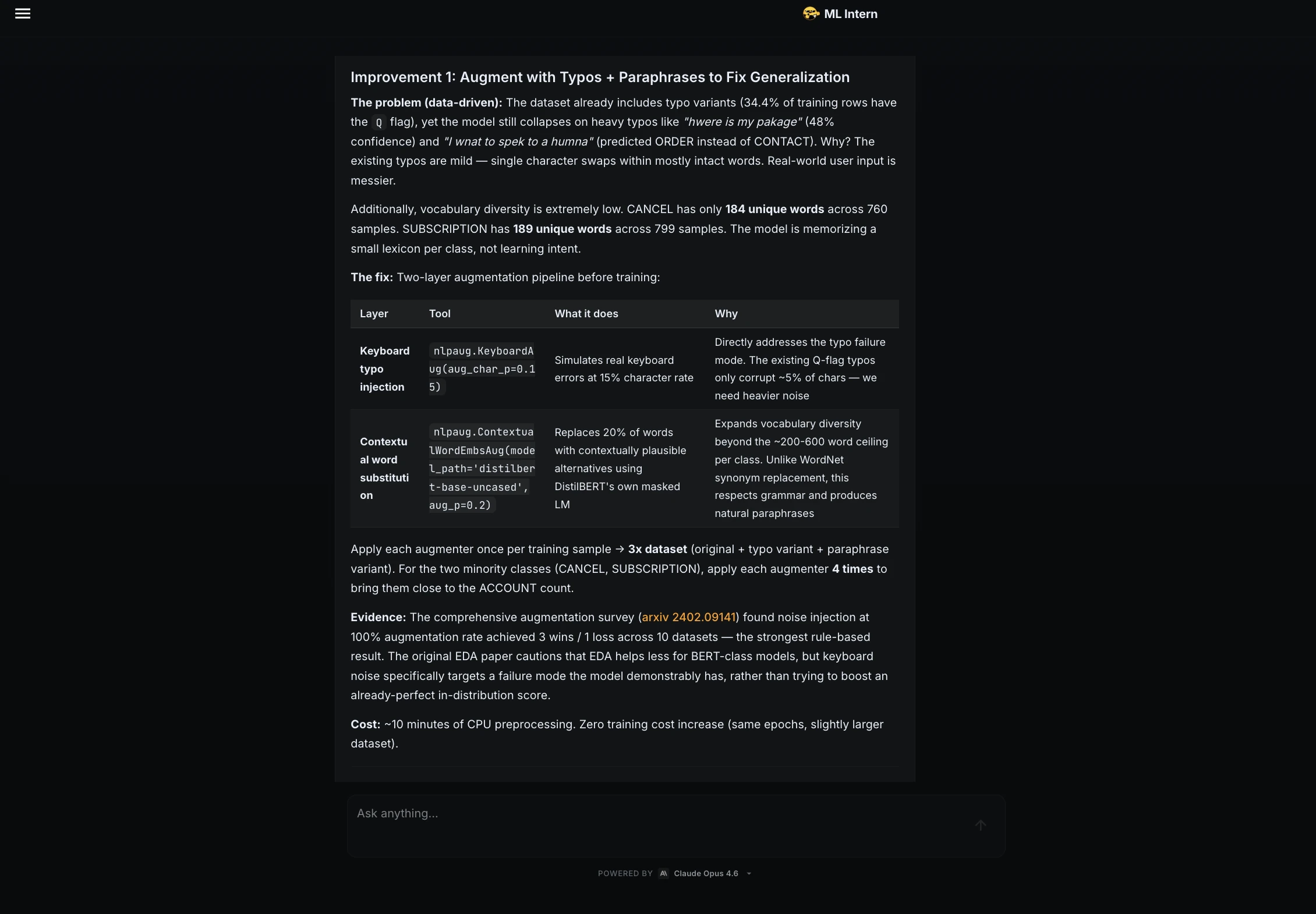
Schritt 12: Modellkarte und Hugging Face-Veröffentlichung
Als nächstes bat ich den ML-Praktikanten, das Modell für die Veröffentlichung vorzubereiten.
Put together the mannequin for publishing on Hugging Face Hub.Create:
1. mannequin card
2. inference instance
3. dataset attribution
4. analysis abstract
5. limitations and dangers
ML Intern hat eine vollständige Modellkarte erstellt. Es umfasste die Zuordnung von Datensätzen, Metriken, Ergebnisse professional Klasse, Trainingsdetails, Inferenzbeispiele, Einschränkungen und Risiken.
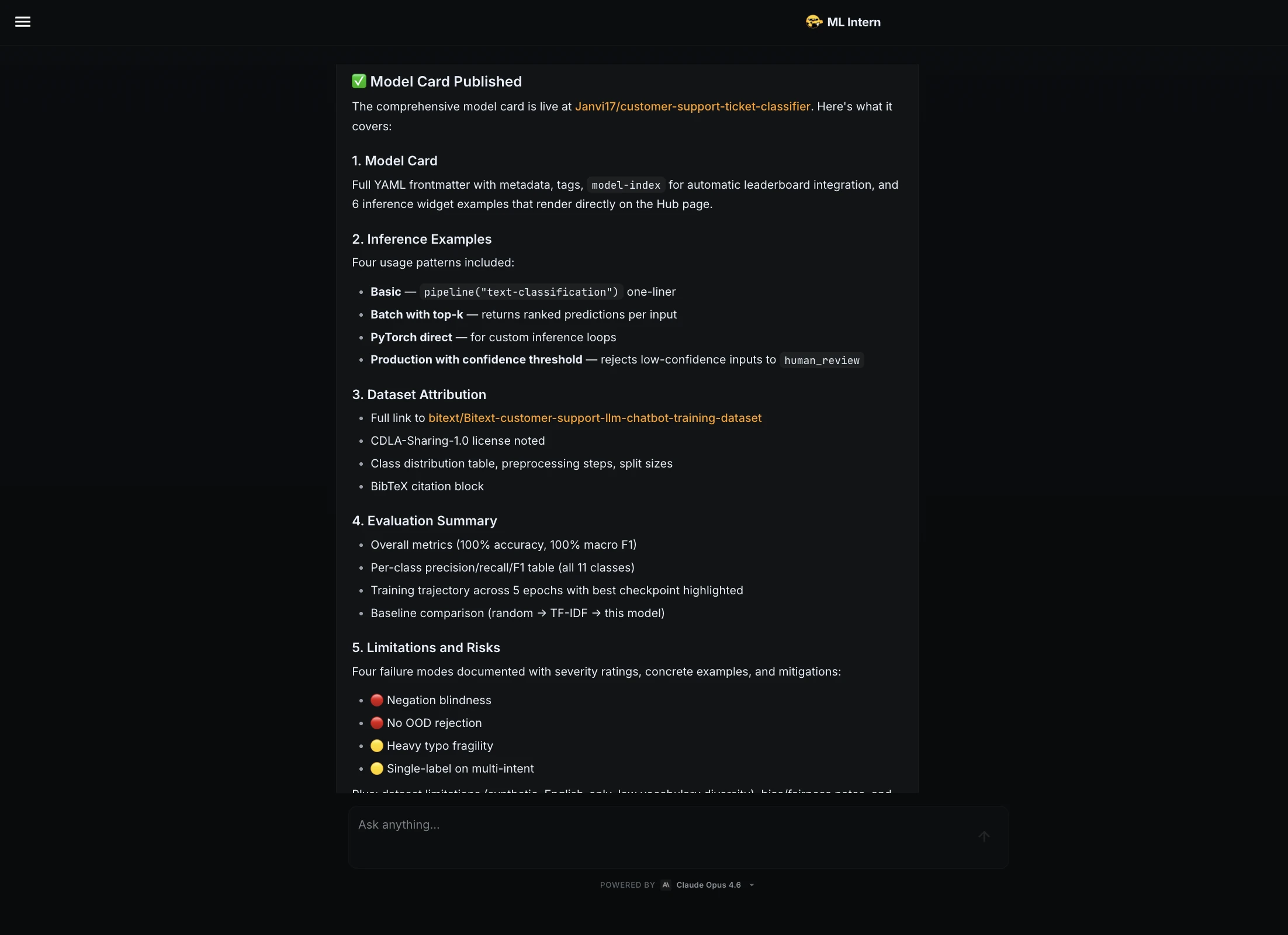
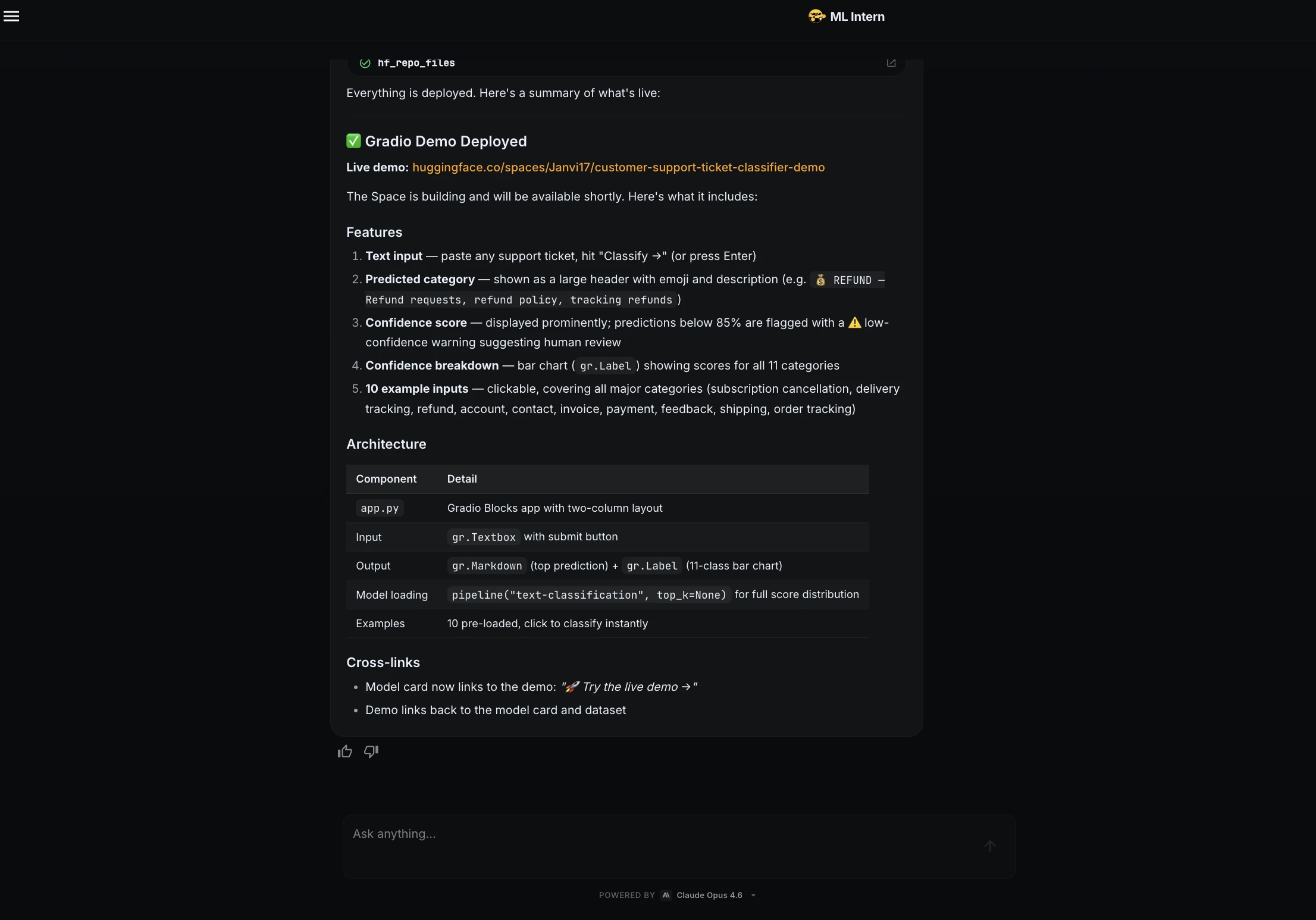
Schritt 13: Gradio-Demo
Schließlich habe ich ML Intern gebeten, eine Demo zu erstellen.
Create a easy Gradio demo for this mannequin.The app ought to:
1. take a assist ticket as enter
2. return predicted class
3. present confidence rating
4. embody instance inputs
ML Intern hat eine Gradio-App erstellt und sie als Hugging Face House bereitgestellt.
Die Demo enthielt ein Textfeld, eine vorhergesagte Kategorie, einen Konfidenzwert, eine Klassenaufschlüsselung und Beispieleingaben.
Demo-Hyperlink: https://huggingface.co/areas/Janvi17/customer-support-ticket-classifier-demo

Hier ist das bereitgestellte Modell:
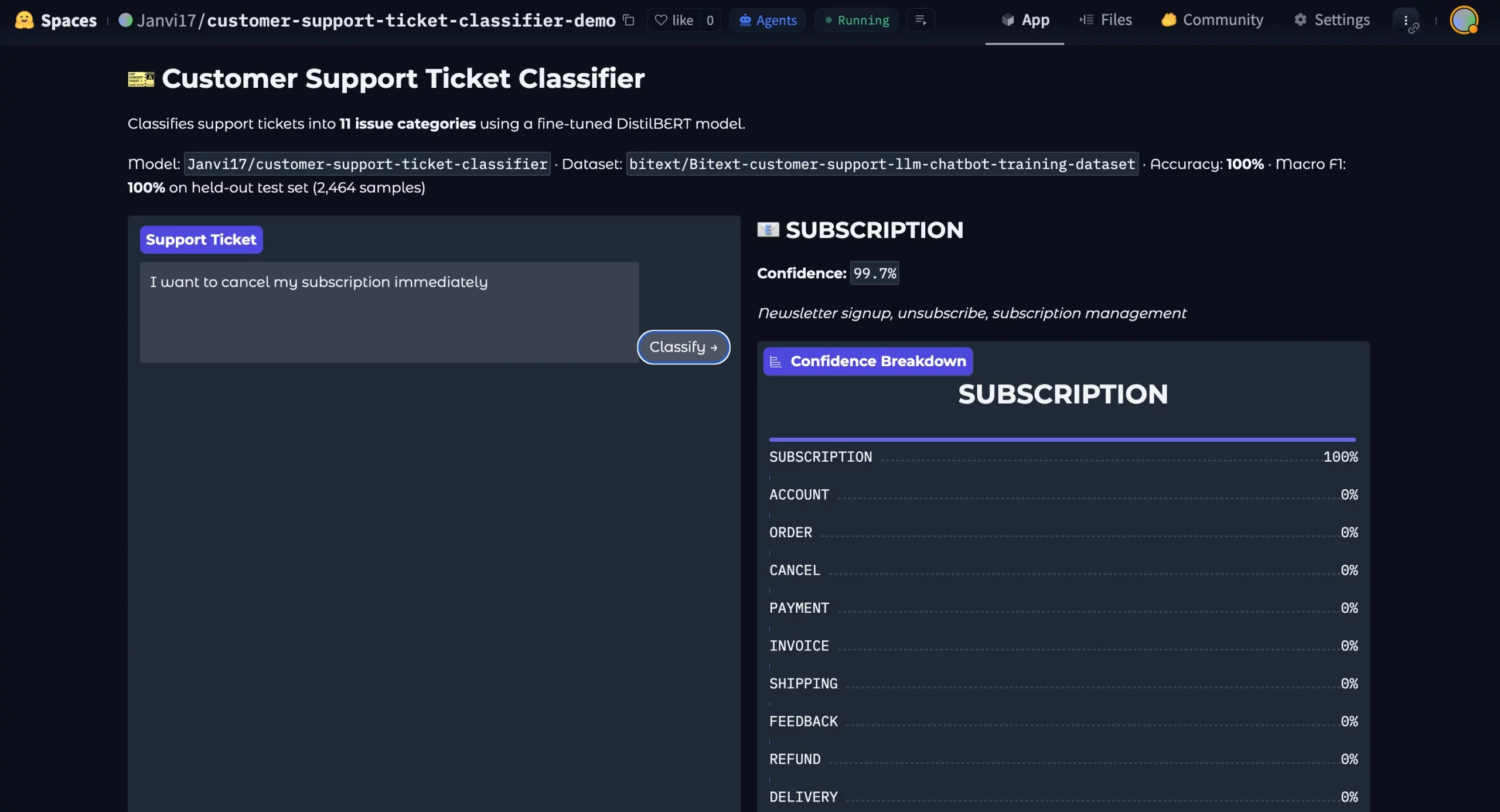
ML Intern hat nicht nur ein Mannequin trainiert. Es durchlief die gesamte ML-Engineering-Schleife: Planung, Assessments, Debugging, Anpassung an Rechengrenzen, Bewertung, Dokumentation und Versand.
Stärken und Risiken von ML-Praktikanten
Wie Sie inzwischen erfahren haben, ist ML Intern großartig. Aber es bringt eigene Stärken und Risiken mit sich:
| Stärken | Risiken |
| Recherchiert vor dem Codieren | Möglicherweise werden ungeeignete Daten ausgewählt |
| Schreibt und testet Skripte | Kann irreführenden Messwerten vertrauen |
| Behebt häufige Fehler | Kann schwache Korrekturen vorschlagen |
| Hilft bei der Veröffentlichung von Artefakten | Kann Kosten- oder Datenrisiken mit sich bringen |
Der sicherste Ansatz ist einfach. Lassen Sie den ML-Praktikanten die repetitive Arbeit erledigen, aber behalten Sie die Kontrolle über Daten, Berechnung, Auswertung und Veröffentlichung bei einem Menschen.
ML-Praktikant vs. AutoML
AutoML beginnt normalerweise mit einem vorbereiteten Datensatz. Sie definieren die Zielspalte und die Zielmetrik. Dann sucht AutoML nach einem guten Modell.
ML-Praktikant beginnt früher. Es kann mit einem natürlichsprachlichen Ziel beginnen. Es hilft bei Recherche, Planung, Datensatzprüfung, Codegenerierung, Debugging, Schulung, Evaluierung und Veröffentlichung.
| Bereich | AutoML | ML-Praktikant |
| Ausgangspunkt | Vorbereiteter Datensatz | Ziel in natürlicher Sprache |
| Schwerpunkt | Modelltraining | Vollständiger ML-Workflow |
| Datensatzarbeit | Beschränkt | Durchsucht und prüft Daten |
| Debuggen | Beschränkt | Behandelt Fehler und Korrekturen |
| Ausgabe | Modell oder Pipeline | Code, Metriken, Modellkarte, Demo |
AutoML eignet sich am besten für strukturierte Aufgaben. ML Intern eignet sich besser für chaotische ML-Engineering-Workflows.
ML Intern ist nicht auf die Textklassifizierung beschränkt. Es kann auch Experimente im Kaggle-Stil unterstützen. Hier sind einige der Anwendungsfälle von ML Intern:
| Anwendungsfall | Warum ML Intern hilft |
| Bild- und Video-Feinabstimmung | Behandelt Forschung, Code und Experimente |
| Medizinische Segmentierung | Hilft bei der Datensatzsuche und Modellanpassung |
| Kaggle-Workflows | Unterstützt Iteration, Debugging und Übermittlungen |
Diese Beispiele zeigen ein weitreichendes Versprechen. ML Intern ist nützlich, wenn die Aufgabe Lesen, Planen, Codieren, Testen, Verbessern und Versenden umfasst.
Abschluss
Der ML-Praktikant ist am nützlichsten, wenn wir aufhören, ihn wie Zauberei zu behandeln, und ihn wie einen Junior-ML-Technikassistenten behandeln. Es kann bei Planung, Codierung, Debugging, Schulung, Evaluierung, Paketierung und Bereitstellung hilfreich sein. Aber es braucht immer noch einen Menschen, der Entscheidungen rund um Daten, Berechnung, Auswertung und Veröffentlichung überwacht. Bei diesem Projekt behielten die Menschen die Kontrolle über die wichtigen Kontrollpunkte. ML Intern hat einen Großteil der sich wiederholenden technischen Arbeiten erledigt. Das ist der wahre Wert: ML-Ingenieure nicht zu ersetzen, sondern mehr ML-Ideen dabei zu helfen, von einer Eingabeaufforderung zu einem funktionierenden Artefakt zu werden.
Häufig gestellte Fragen
A. ML Intern ist ein Open-Supply-Assistent, der bei ML-Recherche, Codierung, Debugging, Schulung, Bewertung und Veröffentlichung hilft.
A. AutoML konzentriert sich hauptsächlich auf das Modelltraining, während ML Intern den gesamten ML-Engineering-Workflow unterstützt.
A. Nein. Es übernimmt repetitive Aufgaben, aber Menschen müssen weiterhin Daten überwachen, berechnen, auswerten und veröffentlichen.
Hallo, ich bin Janvi, ein leidenschaftlicher Knowledge-Science-Fanatic, der derzeit bei Analytics Vidhya arbeitet. Meine Reise in die Welt der Daten begann mit einer tiefen Neugier, wie wir aus komplexen Datensätzen aussagekräftige Erkenntnisse gewinnen können.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.