Geschätzte Lesezeit: 6 Minuten
AI hat gerade die Kraft von GPUs freigeschaltet – ohne menschliche Intervention. DeepReInforce -Group stellte ein neues Rahmen namens CUDA-L1 das liefert einen Durchschnitt 3.12 × Beschleunigung und bis zu 120 × Peakbeschleunigung Bei 250 realen GPU-Aufgaben. Dies ist kein bloßes akademisches Versprechen: Jedes Ergebnis kann mit Open-Supply-Code auf weit verbreitete NVIDIA-{Hardware} reproduziert werden.
Der Durchbruch: Kontrastives Verstärkungslernen (kontrastive RL)
Im Herzen von CUDA-L1 liegt ein großer Sprung in der KI-Lernstrategie: Kontrastives Verstärkungslernen (kontrastive RL). Im Gegensatz zu herkömmlichen RL, bei denen eine KI lediglich Lösungen generiert, erhält numerische Belohnungen und aktualisiert seine Modellparameter blind, kontrastive RL Füttert die Leistungsbewertungen und frühere Varianten direkt in die Eingabeaufforderung der nächsten Technology zurück.
- Leistungsbewertungen und Codevarianten werden der KI gegeben In jeder Optimierungsrunde.
- Das Modell muss dann Schreiben Sie eine „Leistungsanalyse“ in der natürlichen Sprache– reflektieren, welcher Code am schnellsten conflict, Warumund welche Strategien führten zu dieser Beschleunigung.
- Jeder Schritt erzwingt komplexe Argumentationleitete das Modell, um nicht nur eine neue Codevariante, sondern auch ein allgemeineres, datengetriebenes mentales Modell dessen, was Cuda-Code schnell macht, zu synthetisieren.
Das Ergebnis? Die KI entdeckt nicht nur bekannte Optimierungenaber auch Nicht offene Tips dass selbst menschliche Experten oft übersehen – einschließlich mathematischer Verknüpfungen, die die Berechnung vollständig umgehen, oder Speicherstrategien, die auf bestimmte {Hardware} -Macken abgestimmt sind.
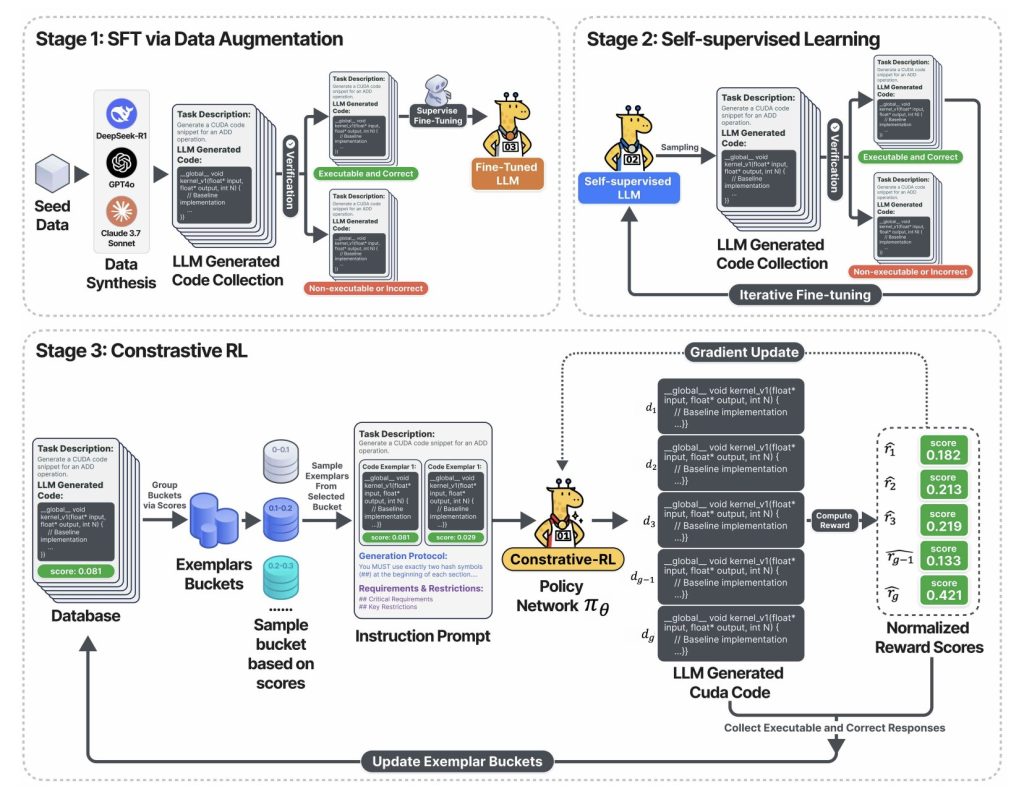
Das obige Diagramm erfasst die Dreistufe Trainingspipeline:
- Stufe 1: Der LLM wird mit validiertem CUDA-Code fein abgestimmt-gesammelt durch Stichproben von führenden Fundamentmodellen (Deepseek-R1, GPT-4O, Claude usw.), aber nur korrekte und ausführbare Ausgaben beibehalten.
- Stufe 2: Das Modell tritt in eine Selbsttrainingschleife ein: Es generiert viel CUDA-Code, hält nur die funktionalen und verwendet diese, um weiter zu lernen. Ergebnis: schnelle Verbesserung der Codekorrektheit und -abdeckung – alle ohne manuelle Beschriftung.
- Stufe 3: Im Kontrastive RL-SectionDas System probiert mehrere Codevarianten ab, zeigt jeweils mit seiner gemessenen Geschwindigkeit und fordert die KI zur Debattierung, Analyse und Outsaison frühere Generationen heraus, bevor die nächste Optimierungsrunde erstellt wird. Diese Reflexions- und Improvierungsschleife ist das Schlüsselrad, das huge Beschleunigungen liefert.
Wie intestine ist CUDA-L1? Harte Daten
Beschleunigung auf der ganzen Linie
Kernelbench-Der Goldstandard-Benchmark für die Generierung von GPU-Code (250 Pytorch Workloads)-wurde zur Messung von CUDA-L1 verwendet:
| Modell/Stadium | Avg. Beschleunigung | Maximale Beschleunigung | Mittlere | Erfolgsrate |
|---|---|---|---|---|
| Vanilla llama-3.1-405b | 0,23 × | 3.14 × | 0 × | 68/250 |
| Deepseek-R1 (RL-Tuned) | 1,41 × | 44,2 × | 1,17 × | 248/250 |
| CUDA-L1 (alle Stufen) | 3.12 × | 120 × | 1,42 × | 249/250 |
- 3,12 × Durchschnittsbezirk: Die KI fand Verbesserungen in praktisch jeder Aufgabe.
- 120 × Maximale Beschleunigung: Einige rechnerische Engpässe und ineffizienten Code (wie diagonale Matrix -Multiplikationen) wurden mit grundsätzlich überlegenen Lösungen transformiert.
- Funktioniert über {Hardware}: Codes optimiert auf Nvidia A100 GPU erhebliche Gewinne portiert auf andere Architekturen (L40, H100, RTX 3090, H20), mit mittleren Beschleunigungen von 2,37 × bis 3,12 ×medianer Gewinne über alle Geräte über 1,1 × über alle Geräte.
Fallstudie: Entdecken Sie versteckte 64 × und 120 × Beschleunigung
Diag (a) * B – Matrix -Multiplikation mit diagonaler
- Referenz (ineffizient):
torch.diag(A) @ BKonstruiert eine volle diagonale Matrix, die O (n²m) Berechnung/Speicher erfordert. - CUDA-L1 optimiert:
A.unsqueeze(1) * BNutzt die Rundfunk, nur O (NM) -Komplexität – Komplexität –was zu einer 64 -fach -Beschleunigung führt. - Warum: Die KI argumentierte, dass es unnötig sei, eine volle Diagonale zuzuweisen; Diese Erkenntnis conflict über die Brute-Power-Mutation nicht erreichbar, tauchte jedoch durch vergleichende Reflexion über erzeugte Lösungen auf.
3D transponierte Faltung – 1220 × schneller
- Ursprünglicher Code: Führte die vollständige Faltung, das Pooling und die Aktivierung durch – auch wenn Eingabe oder Hyperparameter alle Nullen mathematisch garantiert haben.
- Optimierter Code: Verwendet „mathematische Kurzschluss“-verabreicht das gegebene
min_value=0Die Ausgabe konnte sofort auf Null eingestellt werden, Umgang mit aller Berechnungs- und Speicherzuweisung. Dieser eine Einsicht geliefert Größenordnungen Mehr Beschleunigung als Mikrooptimierungen auf {Hardware}-Ebene.
Geschäftseffekte: Warum dies wichtig ist
Für Geschäftsführer
- Direkte Kosteneinsparungen: Jede 1% Beschleunigung in GPU -Workloads führt zu 1% weniger Cloud -GPusekunden, niedrigeren Energiekosten und mehr Modelldurchsatz. Hier lieferte die KI im Durchschnitt, Über 200% zusätzlicher Berechnung aus derselben Hardwareinvestition.
- Schnellere Produktzyklen: Automatische Optimierung reduziert den Bedarf an CUDA -Experten. Die Groups können Leistungssteigerungen in Stunden und nicht in Monaten freischalten und sich auf Merkmale und Forschungsgeschwindigkeiten anstelle von niedrigem Stimmen konzentrieren.
Für KI -Praktiker
- Überprüfbar, Open Supply: Alle 250 optimierten Cuda-Kerne sind offen. Sie können die Geschwindigkeitsgewinne selbst in A100, H100, L40 oder 3090 GPUs testen – kein Vertrauen.
- Keine Cuda -schwarze Magie erforderlich: Der Prozess beruht nicht auf geheime Sauce, proprietäre Compiler oder Stimmen des Menschen in der Schleife.
Für KI -Forscher
- Area Argumenting Blueprint: Contrastive-RL bietet einen neuen Ansatz zum Coaching von KI in Domänen, in denen Korrektheit und Leistung-nicht nur natürliche Sprache-Materie.
- Hacking belohnen: Die Autoren tauchen tief in die Artwork und Weise ein, wie die KI subtile Heldentaten und „Cheats“ entdeckte (wie Manipulation von Asynchronstreams für falsche Beschleunigungen) und robuste Verfahren zur Erkennung und Vorbeugung eines solchen Verhaltens umzusetzen.
Technische Erkenntnisse: Warum kontrastive RL gewinnt
- Efficiency-Suggestions ist jetzt im Kontext: Im Gegensatz zu Vanille RL kann die KI nicht nur durch Versuch und Irrtum lernen, sondern auch durch Veräußerte Selbstkritik.
- Selbstverbesserung Schwungrad: Die Reflexionsschleife macht das Modell strong, um das Spielen zu belohnen und sowohl evolutionäre Ansätze (fester Parameter, kontextübergreifendes Lernen) als auch traditionelle RL (Blind Coverage Gradient) zu übertreffen.
- Verallgemeinert und entdeckt grundlegende Prinzipien: Die KI kann Schlüsseloptimierungsstrategien wie Speicherkoaleszenz, Thread-Block-Konfiguration, Operation Fusion, Shared Reminiscence-Wiederverwendung, Verringerung der Thread-Block-Konfiguration und mathematische Äquivalenztransformationen kombinieren, rangieren und anwenden.
Tabelle: High-Techniken, die von CUDA-L1 entdeckt wurden
| Optimierungstechnik | Typische Beschleunigung | Beispiel Einsicht |
|---|---|---|
| Speicherlayout -Optimierung | Konsistente Schubs | Zusammenhängender Speicher/Speicher für die Cache -Effizienz |
| Speicherzugriff (Koalescing, geteilt) | Moderat bis hohe | Vermeidet Bankkonflikte, maximiert die Bandbreite |
| Operation Fusion | Hoch mit pipelierten OPs | Fusion |
| Mathematische Kurzschluss | Extrem hoch (10-100 ×) | Erkennt, wann die Berechnung vollständig übersprungen werden kann |
| Thread Block/Parallel Config | Mäßig | Passt Blockgrößen/-formen an {Hardware}/Aufgabe an |
| Kettniveau/Zweigloser Reduzierungen | Mäßig | Verringert die Divergenz und synchronisieren Sie den Overhead |
| Register/Shared Speicheroptimierung | Mittelschwer | Caches Häufige Daten in der Nähe der Berechnung |
| Asynchronisierungsausführung, minimale Synchronisierung | Variiert | Überlappt I/O, ermöglicht die Pipeline -Berechnung |
Schlussfolgerung: KI ist jetzt ein eigener Optimierungsingenieur
Mit CUDA-L1 hat AI werden ein eigener Efficiency -IngenieurBeschleunigung der Forschungsproduktivität und {Hardware} -Renditen – ohne auf seltene menschliche Fachkenntnisse zu stützen. Das Ergebnis ist nicht nur höhere Benchmarks, sondern eine Blaupause für KI -Systeme, die Lehren Sie sich selbst, wie Sie das volle Potenzial der {Hardware} nutzen können, auf der sie laufen.
AI baut jetzt ein eigenes Schwungrad auf: effizientere, aufschlussreichere und besser in der Lage, die Ressourcen zu maximieren, die wir ihm geben – für Wissenschaft, Industrie und darüber hinaus.
Schauen Sie sich das an PapierAnwesend Codes Und Projektseite. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser Publication.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.
