

Bild vom Autor
# Einführung
Sie erstellen eine LLM-basierte Funktion, die perfekt auf Ihrer Maschine funktioniert. Die Antworten sind schnell, präzise und alles fühlt sich reibungslos an. Dann setzt man es ein und plötzlich ändern sich die Dinge. Die Reaktionen verlangsamen sich. Die Kosten beginnen schleichend zu steigen. Benutzer stellen Fragen, mit denen Sie nicht gerechnet haben. Das Modell liefert Antworten, die auf den ersten Blick intestine aussehen, aber echte Arbeitsabläufe stören. Was in einer kontrollierten Umgebung funktioniert hat, beginnt bei der realen Nutzung auseinanderzufallen.
Hier stoßen die meisten Projekte an ihre Grenzen. Die Herausforderung besteht nicht darin, ein Sprachmodell zum Laufen zu bringen. Dieser Teil ist einfacher als je zuvor. Die eigentliche Herausforderung besteht darin, es zuverlässig, skalierbar und nutzbar in einer Produktionsumgebung zu machen, in der die Eingaben chaotisch, die Erwartungen hoch sind und Fehler tatsächlich eine Rolle spielen.
Bei der Bereitstellung geht es nicht nur um den Aufruf einer API oder das Hosten eines Modells. Dabei geht es um Entscheidungen zu Architektur, Kosten, Latenz, Sicherheit und Überwachung. Jeder dieser Faktoren kann sich darauf auswirken, ob Ihr System mit der Zeit hält oder stillschweigend ausfällt. Viele Groups unterschätzen diese Lücke. Sie konzentrieren sich stark auf Eingabeaufforderungen und die Modellleistung, verbringen jedoch viel weniger Zeit damit, darüber nachzudenken, wie sich das System verhält, wenn echte Benutzer beteiligt sind. Hier sind 7 praktische Schritte für den Übergang vom Prototypen zum produktionsreifen LLM-System.
# Schritt 1: Den Anwendungsfall klar definieren
Die meisten Bereitstellungsprobleme beginnen, bevor Code geschrieben wird. Wenn der Anwendungsfall vage ist, wird alles, was folgt, schwieriger. Am Ende überdimensionieren Sie Teile des Programs und verpassen dabei das Wesentliche.
Klarheit bedeutet hier, das Downside einzugrenzen. Anstatt zu sagen: „Erstellen Sie einen Chatbot„Definieren Sie genau, was dieser Chatbot tun soll. Beantwortet er häufig gestellte Fragen, bearbeitet Help-Tickets oder führt er Benutzer durch ein Produkt? Jeder dieser Schritte erfordert einen anderen Ansatz.
Auch die Enter- und Output-Erwartungen müssen klar sein. Welche Artwork von Daten werden Benutzer bereitstellen? Welches Format sollte die Antwort haben – Freiformtext, strukturiertes JSON oder etwas ganz anderes? Diese Entscheidungen wirken sich darauf aus, wie Sie Eingabeaufforderungen, Validierungsebenen und sogar Ihre Benutzeroberfläche entwerfen.
Ebenso wichtig sind Erfolgskennzahlen. Ohne sie ist es schwer zu wissen, ob das System funktioniert. Das können Antwortgenauigkeit, Aufgabenerledigungsrate, Latenz oder sogar Benutzerzufriedenheit sein. Je klarer die Metrik, desto einfacher ist es, später Kompromisse einzugehen.
Ein einfaches Beispiel macht dies deutlich. Ein Allzweck-Chatbot ist umfangreich und unvorhersehbar. Ein strukturierter Datenextraktor hingegen verfügt über klare Ein- und Ausgänge. Es ist einfacher zu testen, einfacher zu optimieren und einfacher zuverlässig bereitzustellen. Je spezifischer Ihr Anwendungsfall, desto einfacher wird alles andere.
# Schritt 2: Auswahl des richtigen Modells (nicht des größten)
Sobald der Anwendungsfall klar ist, ist die nächste Entscheidung das Modell selbst. Es kann verlockend sein, sich direkt für das leistungsstärkste verfügbare Modell zu entscheiden. Größere Modelle schneiden in Benchmarks tendenziell besser ab, aber in der Produktion ist das nur ein Teil der Gleichung. Kosten ist oft die erste Einschränkung. Größere Modelle sind im Betrieb teurer, insbesondere im Maßstab. Was beim Testen überschaubar erscheint, kann zu einem erheblichen Kostenfaktor werden, sobald echter Datenverkehr eintrifft.
Latenz ist ein weiterer Faktor. Bei größeren Modellen dauert die Reaktion in der Regel länger. Bei benutzerorientierten Anwendungen können bereits kleine Verzögerungen das Erlebnis beeinträchtigen. Genauigkeit ist immer noch wichtig, aber es muss im Kontext betrachtet werden. Ein etwas leistungsschwächeres Modell, das Ihre spezifische Aufgabe intestine erfüllt, ist möglicherweise die bessere Wahl als ein größeres Modell, das allgemeiner, aber langsamer und teurer ist.
Hinzu kommt die Entscheidung zwischen gehosteten APIs und Open-Supply-Modellen. Gehostete APIs sind einfacher zu integrieren und zu warten, Sie müssen jedoch etwas Kontrolle einbüßen. Open-Supply-Modelle bieten Ihnen mehr Flexibilität und können die langfristigen Kosten senken, erfordern jedoch mehr Infrastruktur und betrieblichen Aufwand. In der Praxis ist selten das größte Modell die beste Wahl. Es ist diejenige, die zu Ihrem Anwendungsfall, Funds und Ihren Leistungsanforderungen passt.
# Schritt 3: Entwerfen Ihrer Systemarchitektur
Sobald Sie über einen einfachen Prototyp hinausgehen, ist das Modell nicht mehr das System. Es wird zu einer Komponente innerhalb einer größeren Architektur. LLMs sollten nicht isoliert agieren. Ein typischer Produktionsaufbau umfasst eine API-Schicht das eingehende Anfragen bearbeitet, die Modell sich selbst für Technology, a Retrieval-Schicht für Erdungsreaktionen und a Datenbank zum Speichern von Daten, Protokollen oder Benutzerstatus. Jeder Teil trägt dazu bei, das System zuverlässig und skalierbar zu machen.
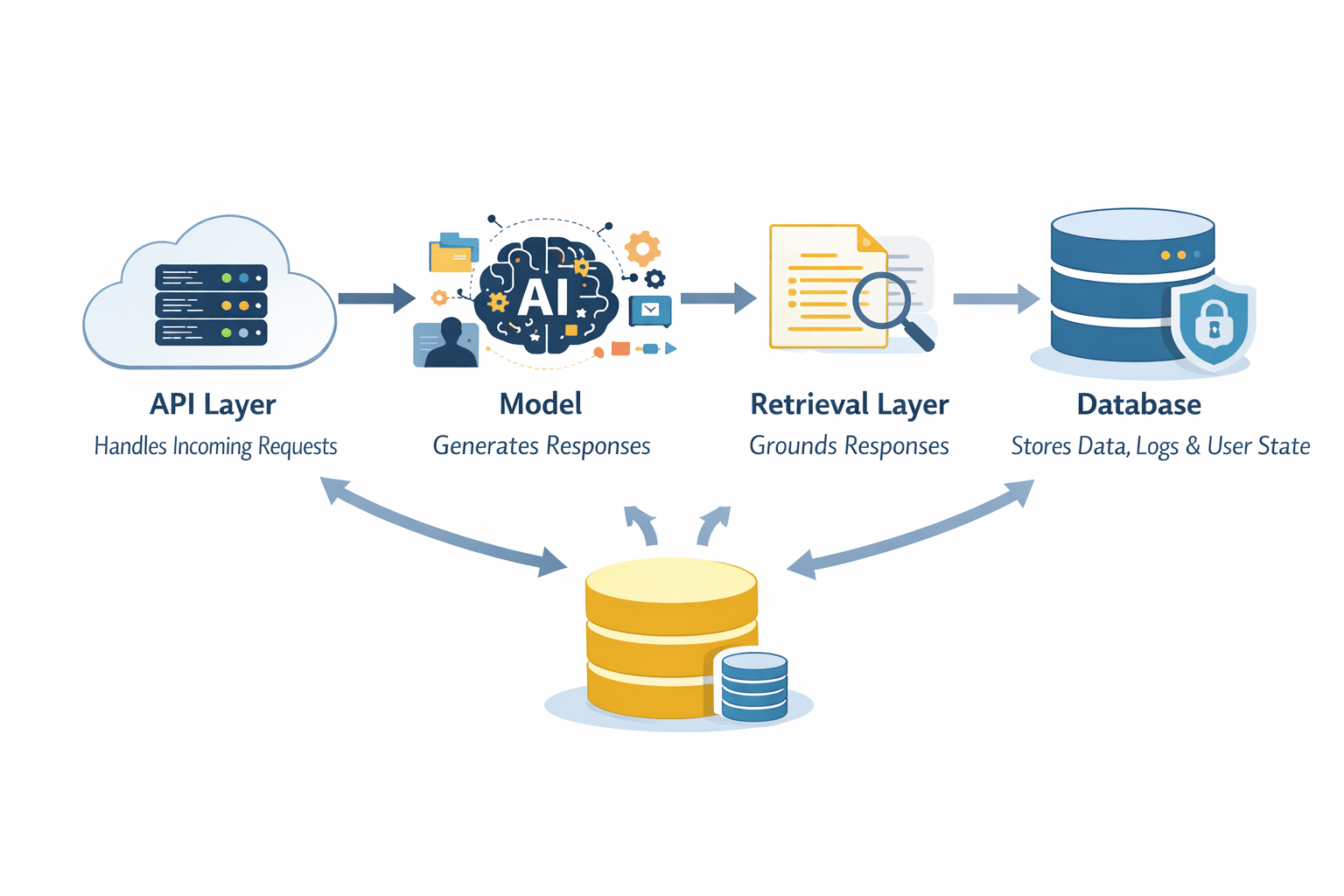
Schichten in einer Systemarchitektur | Bild vom Autor
Der API-Schicht fungiert als Einstiegspunkt. Es verwaltet Anfragen, übernimmt die Authentifizierung und leitet Eingaben an die richtigen Komponenten weiter. Hier können Sie Grenzwerte durchsetzen, Eingaben validieren und steuern, wie auf das System zugegriffen wird.
Der Modell sitzt in der Mitte, muss aber nicht alles können. Retrieval-Systeme können relevanten Kontext aus externen Datenquellen bereitstellen, Halluzinationen reduzieren und die Genauigkeit verbessern. Datenbanken Speichern Sie strukturierte Daten, Benutzerinteraktionen und Systemausgaben, die später wiederverwendet werden können.
Eine weitere wichtige Entscheidung ist, ob Ihr System zustandslos oder zustandsbehaftet ist. Staatenlose Systeme Behandeln Sie jede Anfrage unabhängig voneinander, was die Skalierung erleichtert. Zustandsbehaftete Systeme Behalten Sie den Kontext über Interaktionen hinweg bei, was die Benutzererfahrung verbessern kann, aber die Komplexität bei der Speicherung und dem Abruf von Daten erhöht.
Hier hilft das Denken in Pipelines. Anstelle eines Schritts, der eine Antwort generiert, entwerfen Sie einen Ablauf. Eingaben gehen ein, bestehen die Validierung, werden mit Kontext angereichert, vom Modell verarbeitet und verarbeitet, bevor sie zurückgegeben werden. Jeder Schritt ist kontrolliert und beobachtbar.
# Schritt 4: Leitplanken und Sicherheitsebenen hinzufügen
Selbst bei einer soliden Architektur sollte die Rohmodellausgabe niemals direkt an Benutzer gehen. Sprachmodelle sind leistungsstark, aber nicht grundsätzlich sicher oder zuverlässig. Ohne Einschränkungen können sie falsche, irrelevante oder sogar schädliche Reaktionen hervorrufen.
Leitplanken halten das unter Kontrolle.
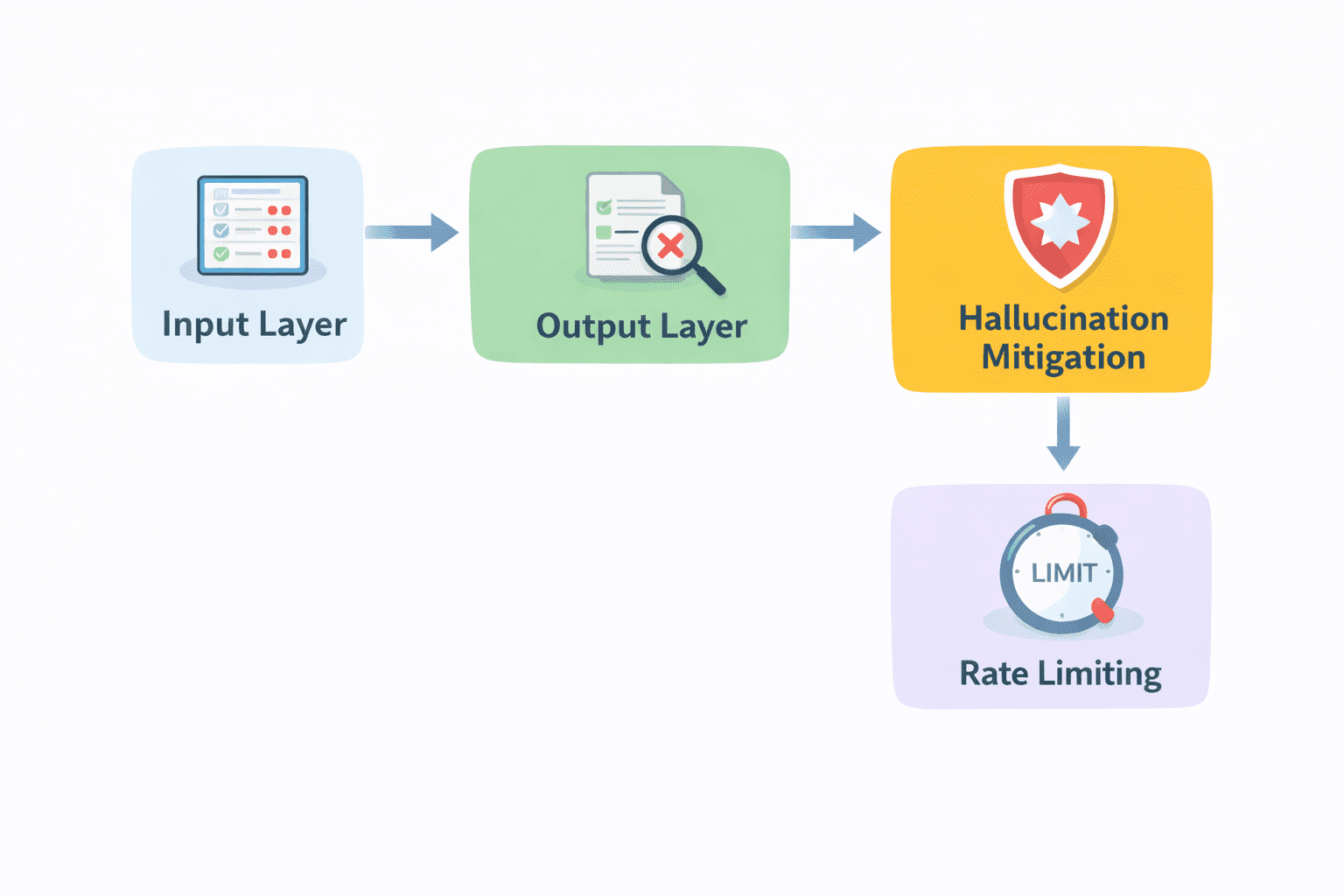
Leitplanken und Sicherheitsschichten | Bild vom Autor
- Eingabevalidierung ist die erste Schicht. Bevor eine Anfrage das Modell erreicht, sollte sie geprüft werden. Ist die Eingabe gültig? Entspricht es den erwarteten Formaten? Gibt es Versuche, das System zu missbrauchen? Das Filtern in dieser Part verhindert unnötige oder riskante Anrufe.
- Ausgabefilterung kommt als nächstes. Nachdem das Modell eine Antwort generiert hat, sollte diese vor der Übermittlung überprüft werden. Dies kann die Prüfung auf schädliche Inhalte, die Durchsetzung von Formatierungsregeln oder die Validierung bestimmter Felder in strukturierten Ausgaben umfassen.
- Linderung von Halluzinationen ist ebenfalls Teil dieser Schicht. Hier können Techniken wie Abruf, Verifizierung oder eingeschränkte Generierung angewendet werden, um die Wahrscheinlichkeit zu verringern, dass falsche Antworten den Benutzer erreichen.
- Ratenbegrenzung ist ein weiterer praktischer Schutz. Es schützt Ihr System vor Missbrauch und hilft bei der Kostenkontrolle, indem es die Anzahl der möglichen Anfragen begrenzt.
Ohne Leitplanken kann selbst ein starkes Modell zu Ergebnissen führen, die das Vertrauen zerstören oder Risiken schaffen. Mit den richtigen Schichten verwandeln Sie die Roherzeugung in etwas Kontrolliertes und Zuverlässiges.
# Schritt 5: Optimierung hinsichtlich Latenz und Kosten
Sobald Ihr System dwell ist, ist die Leistung kein technisches Element mehr, sondern ein Downside für den Benutzer. Langsame Antworten frustrieren Benutzer. Hohe Kosten schränken die Skalierung ein. Beides kann ein ansonsten festes Produkt stillschweigend töten.
Caching ist eine der einfachsten Möglichkeiten, beides zu verbessern. Wenn Benutzer ähnliche Fragen stellen oder ähnliche Arbeitsabläufe auslösen, müssen Sie nicht jedes Mal eine neue Antwort generieren. Durch das Speichern und Wiederverwenden von Ergebnissen können sowohl Latenz als auch Kosten erheblich reduziert werden.
Das Streamen von Antworten trägt auch zur wahrgenommenen Leistung bei. Anstatt auf die vollständige Ausgabe zu warten, sehen Benutzer die Ergebnisse bereits bei der Generierung. Selbst wenn die Gesamtverarbeitungszeit gleich bleibt, fühlt sich das Erlebnis schneller an.
Ein weiterer praktischer Ansatz ist die dynamische Auswahl von Modellen. Nicht jede Anfrage benötigt das leistungsstärkste Modell. Einfachere Aufgaben können von kleineren, günstigeren Modellen erledigt werden, während komplexere Aufgaben an stärkere Modelle weitergeleitet werden können. Durch diese Artwork des Routings bleiben die Kosten unter Kontrolle, ohne dass die Qualität dort beeinträchtigt wird, wo es darauf ankommt.
Die Stapelverarbeitung ist in Systemen nützlich, die mehrere Anfragen gleichzeitig bearbeiten. Anstatt jede Anfrage einzeln zu bearbeiten, kann die Gruppierung die Effizienz verbessern und den Overhead reduzieren.
Der rote Faden bei all dem ist die Ausgewogenheit. Sie optimieren nicht nur isoliert auf Geschwindigkeit oder Kosten. Sie erreichen einen Punkt, an dem das System reaktionsfähig bleibt und gleichzeitig wirtschaftlich rentabel bleibt.
# Schritt 6: Überwachung und Protokollierung implementieren
Sobald das System läuft, benötigen Sie Einblick in das Geschehen, denn ohne es arbeiten Sie blind. Das Fundament ist Protokollierung. Jede Anfrage und Antwort sollte so nachverfolgt werden, dass Sie überprüfen können, was das System tut. Dazu gehören Benutzereingaben, Modellausgaben und alle Zwischenschritte in der Pipeline. Wenn etwas schiefgeht, sind diese Protokolle oft die einzige Möglichkeit, den Grund dafür zu verstehen.
Darauf baut die Fehlerverfolgung auf. Anstatt Protokolle manuell zu scannen, sollte das System Fehler automatisch aufdecken. Dies können Zeitüberschreitungen, ungültige Ausgaben oder unerwartetes Verhalten sein. Wenn Sie diese frühzeitig erkennen, verhindern Sie, dass kleine Probleme zu größeren Problemen werden.
Ebenso wichtig sind Leistungskennzahlen. Sie müssen wissen, wie lange Antworten dauern, wie oft Anfragen erfolgreich sind und wo Engpässe bestehen. Mithilfe dieser Kennzahlen können Sie Bereiche identifizieren, die optimiert werden müssen.
Benutzerfeedback fügt eine weitere Ebene hinzu. Manchmal scheint das System aus technischer Sicht korrekt zu funktionieren, liefert aber dennoch schlechte Ergebnisse. Suggestions-Signale, seien es explizite Bewertungen oder implizites Verhalten, helfen Ihnen zu verstehen, wie intestine das System aus Sicht des Benutzers tatsächlich funktioniert.
# Schritt 7: Iterieren mit echtem Benutzerfeedback
Sie müssen wissen, dass die Bereitstellung nicht das Ziel ist. Hier beginnt die eigentliche Arbeit. Egal wie intestine Sie Ihr System entwerfen, echte Benutzer werden es auf eine Weise nutzen, die Sie nicht erwartet haben. Sie werden unterschiedliche Fragen stellen, unordentliche Eingaben bereitstellen und das System in Grenzfälle treiben, die beim Testen nie aufgetaucht sind.
Hier wird die Iteration entscheidend. A/B-Assessments ist eine Möglichkeit, dies anzugehen. Sie können verschiedene Eingabeaufforderungen, Modellkonfigurationen oder Systemabläufe mit echten Benutzern testen und die Ergebnisse vergleichen. Anstatt zu raten, was funktioniert, messen Sie es.
Prompte Iteration wird in dieser Part ebenfalls fortgesetzt, jedoch auf eine fundiertere Artwork und Weise. Anstatt isoliert zu optimieren, verfeinern Sie Eingabeaufforderungen auf der Grundlage tatsächlicher Nutzungsmuster und Fehlerfälle. Das Gleiche gilt auch für andere Teile des Programs. Abrufqualität, Leitplanken und Routing-Logik können im Laufe der Zeit verbessert werden.
Der wichtigste Enter hierbei ist das Nutzerverhalten. Worauf Benutzer klicken, wo sie abbrechen, was sie wiederholen und worüber sie sich beschweren. Diese Signale offenbaren Probleme, die durch Metriken allein möglicherweise übersehen werden, und im Laufe der Zeit entsteht eine Schleife. Benutzer interagieren mit dem System, das System sammelt Signale und diese Signale führen zu Verbesserungen. Mit jeder Iteration wird das System besser an die reale Nutzung angepasst.

Diagramm, das einen einfachen Finish-to-Finish-Ablauf eines Produktions-LLM-Programs zeigt | Bild vom Autor
# Zusammenfassung
Wenn Sie die Produktion erreichen, wird klar, dass die Bereitstellung von Sprachmodellen nicht nur ein technischer Schritt ist. Es ist eine Designherausforderung. Das Modell ist wichtig, aber es ist nur ein Teil. Entscheidend für den Erfolg ist, wie intestine alles drumherum zusammenspielt. Die Architektur, die Leitplanken, die Überwachung und der Iterationsprozess spielen alle eine Rolle dabei, wie zuverlässig das System wird.
Bei starken Bereitstellungen steht zunächst die Zuverlässigkeit im Vordergrund. Sie stellen sicher, dass sich das System unter verschiedenen Bedingungen konsistent verhält. Sie sind skalierbar, ohne dass sie bei zunehmender Nutzung kaputt gehen. Und sie sind darauf ausgelegt, sich im Laufe der Zeit durch kontinuierliches Suggestions und Iteration zu verbessern, und das ist es, was funktionierende Systeme von fragilen unterscheidet.
Shittu Olumide ist ein Software program-Ingenieur und technischer Autor, der sich leidenschaftlich dafür einsetzt, modernste Technologien zu nutzen, um fesselnde Erzählungen zu erschaffen, mit einem scharfen Blick fürs Element und einem Gespür für die Vereinfachung komplexer Konzepte. Sie können Shittu auch auf finden Twitter.