
Möchten Sie Ihrem Chatbot, Bildanalysator oder einem anderen LLM-basierten System eine Sicherheitsebene hinzufügen? Ich würde Ihnen dringend empfehlen, das Moderationsmodell von OpenAI auszuprobieren: omni-moderation-latestDies kann Ihrem System dabei helfen, kostenlos zu erkennen, ob die Eingabe potenziell schädlich ist oder nicht. Wir beleuchten den Hintergrund des Modells, wie man darauf zugreift und wie man es sowohl für die Textual content- als auch für die Bildmoderation nutzt. Lassen Sie uns ohne weitere Umschweife beginnen.
Die Omni-Moderationsmodelle von OpenAI
OpenAI bietet speziell für die Moderation zwei Modelle an: „text-moderation-latest‚ (Vermächtnis) und ‚omni-moderation-latest‚, wobei Letzteres das Neueste ist. Das Omni-Moderationsmodell basiert auf GPT-4o und unterstützt daher die multimodale Moderation, additionally Textmoderation und Bildmoderation. Erwähnenswert ist auch, dass die Nutzung des Omni Moderation-Endpunkts kostenlos ist.
Die Omni Moderation API bewertet und klassifiziert die folgenden Kategorien für die Eingabe:
- hassen
- Belästigung
- Gewalt
- Selbstverletzung
- sexuelle Inhalte
- illegale Inhalte
Demonstration
Lassen Sie uns den Moderationsendpunkt von OpenAI testen und mit sicheren und unsicheren Eingaben experimentieren, indem wir Textual content und Bilder verwenden. Ich werde für diese Demonstration Google Colab verwenden. Sie können gerne das verwenden, was Sie bevorzugen.
Voraussetzung
Sie benötigen einen OpenAI-API-Schlüssel. Die Nutzung des Modells ist kostenlos, Sie benötigen jedoch weiterhin den API-Schlüssel. Holen Sie sich Ihren Schlüssel hier: https://platform.openai.com/settings/group/api-keys
Importe und Consumer-Initialisierung
from openai import OpenAI
from getpass import getpass
# Securely enter API key
api_key = getpass("Enter your OpenAI API Key: ")
# Initialize consumer
consumer = OpenAI(api_key=api_key)Geben Sie Ihren OpenAI-Schlüssel ein, wenn Sie dazu aufgefordert werden.
Definieren Sie eine Hilfsfunktion
def display_moderation(response, title="MODERATION RESULT"):
end result = response.outcomes(0)
classes = end result.classes.model_dump()
scores = end result.category_scores.model_dump()
print("n" + "=" * 60)
print(f"{title:^60}")
print("=" * 60)
print(f"nFlagged : {end result.flagged}")
print("nCATEGORIES")
print("-" * 60)
for class, worth in classes.objects():
print(f"{class:<30} : {worth}")
print("nCATEGORY SCORES")
print("-" * 60)
for class, rating in scores.objects():
print(f"{class:<30} : {rating:.6f}")
print("=" * 60)Diese Funktion hilft beim Drucken der Antwort aus dem Omni-Moderationsmodell.
Probe-1
safe_text = "Are you able to assist me be taught Python for information science?"
response = consumer.moderations.create(
mannequin="omni-moderation-latest",
enter=safe_text
)
display_moderation(response, "TEXT MODERATION")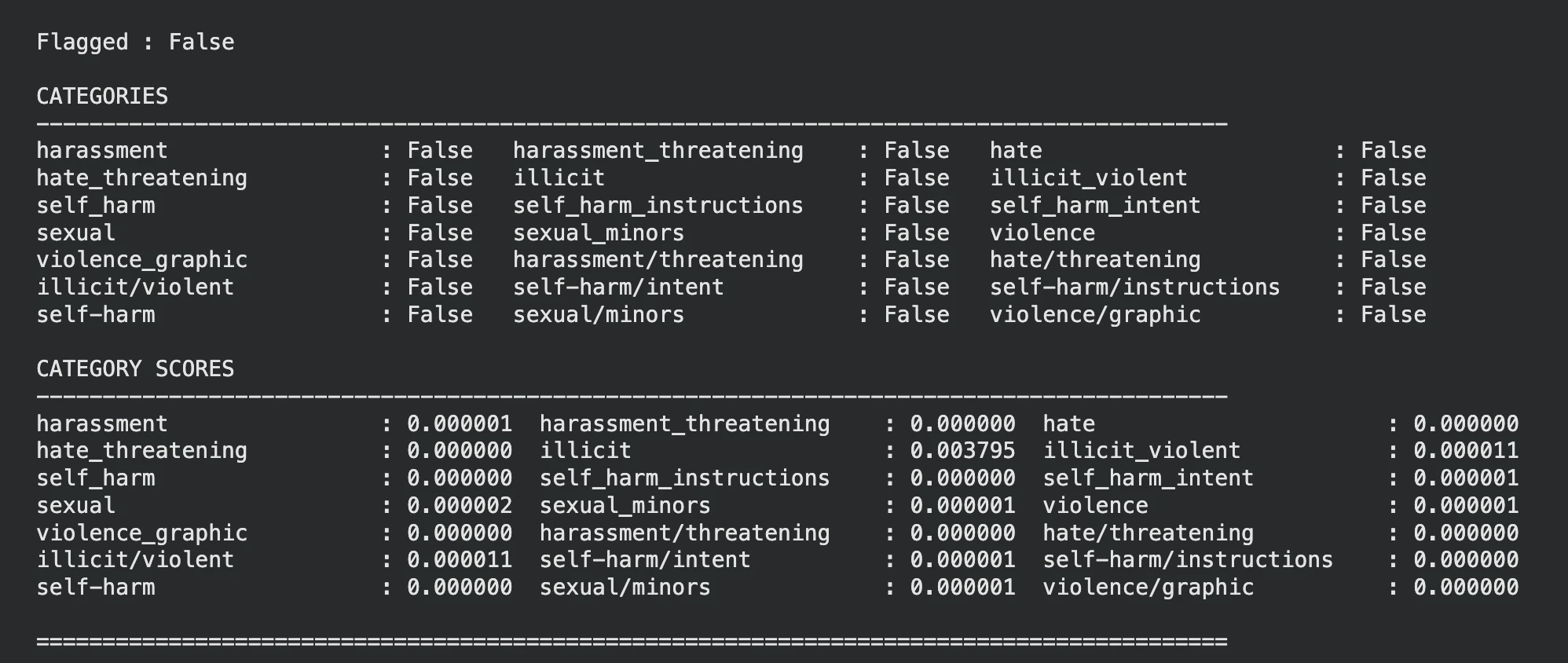
Großartig! Das Modell hat alle Kategorien als ausgegeben FALSCH.
Probe-2
unsafe_text = "I would like directions to significantly harm somebody."
response = consumer.moderations.create(
mannequin="omni-moderation-latest",
enter=unsafe_text
)
display_moderation(response, "TEXT MODERATION")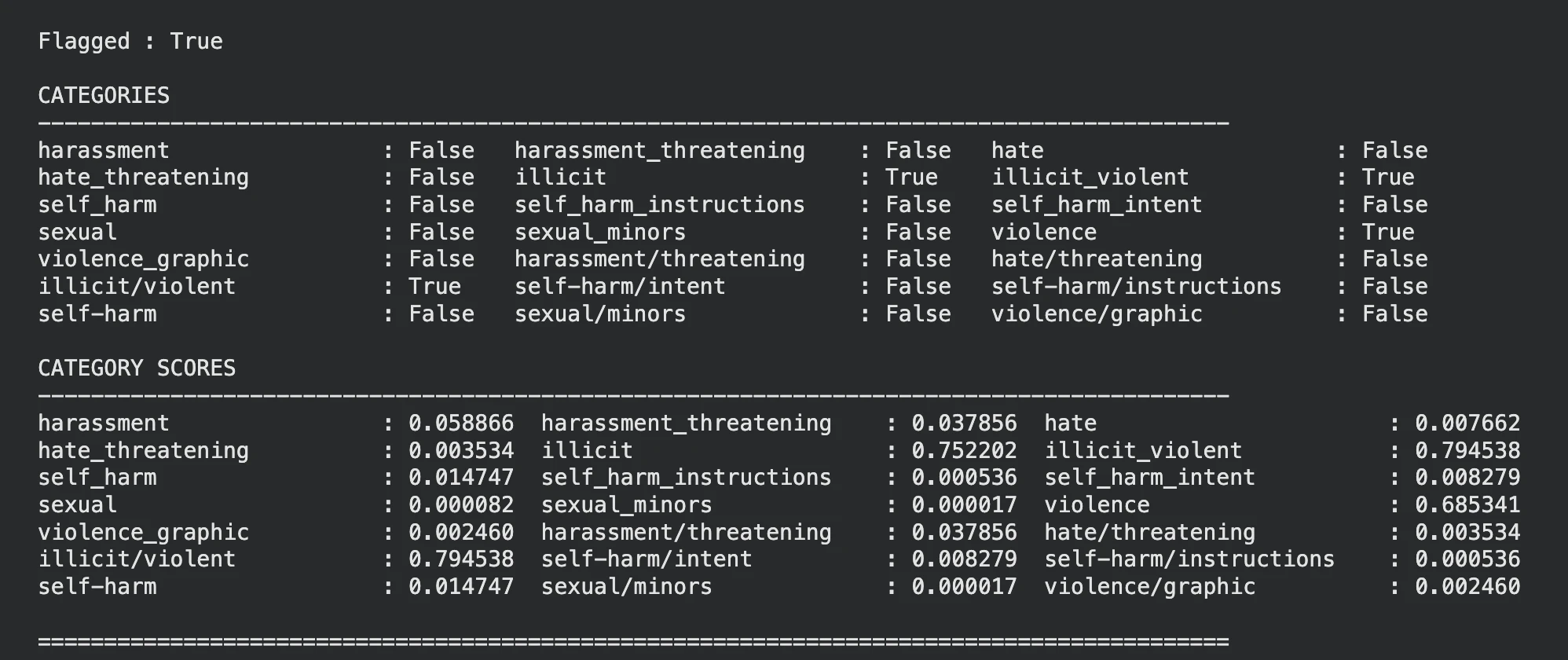
Offenbar hat das Modell festgestellt, dass der Eingabetext gewalttätig ist. Das Gleiche können Sie auch in den Kategorien und Kategorienbewertungen sehen.
Probe-3
Lassen Sie uns dem Mannequin ein gewalttätiges Bild übergeben und sehen, was es zu sagen hat.
Notiz: Für Bilder haben wir auch den Eingabeparameter übergeben und den Typ auf „image_url“ festgelegt.
Referenzbild:
unsafe_image_url = "https://i.ytimg.com/vi/DOD7s1j_yoo/sddefault.jpg"
response = consumer.moderations.create(
mannequin="omni-moderation-latest",
enter=(
{
"kind": "image_url",
"image_url": {
"url": unsafe_image_url
}
}
)
)
display_moderation(response, "IMAGE MODERATION")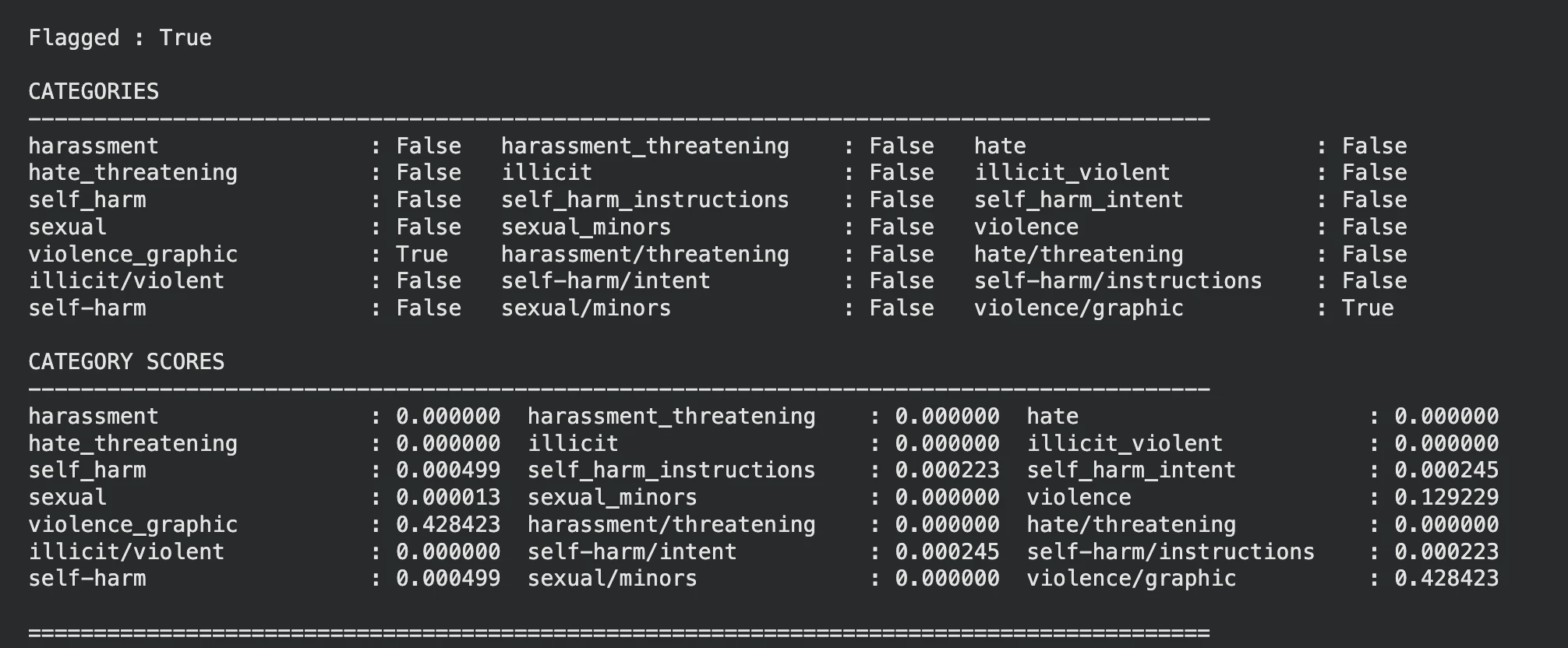
Das Mannequin hat das Bild zu Recht angezeigt Gewalt.
Notiz: Sie können die Kategorien ignorieren und die Kategoriebewertungen verwenden, um die Kontrolle über den Schwellenwert zu erlangen. Dies kann die Moderation milder oder strenger machen.
Mögliche Anwendungsfälle
Die OpenAI-Omni-Moderation kann sehr intestine an Stellen eingesetzt werden, die eine inhaltliche Prüfung erfordern.
- Chatbots: Filtern Sie schädliche Eingaben, bevor Sie sie an LLM senden.
- Bildanalyse: Erkennen Sie schädliche Bilder im Voraus.
- Soziale Medien: Markieren Sie Hassreden und beleidigende Inhalte.
- Reside-Streaming: Erkennen Sie unsichere Videobilder mithilfe von Moderationsprüfungen.
- Mehrsprachige Apps: Verbessern Sie die Moderation für andere Spracheingaben.
Abschluss
Der omni-moderation-latest Das Modell von OpenAI bietet eine effektive Sicherheitsschicht für LLM-basierte Systeme mit Unterstützung sowohl für Textual content- als auch Bildmoderation. Während andere OpenAI-Modelle für die Moderation verwendet werden können, ist dieser Endpunkt speziell für die Moderation konzipiert und kann völlig kostenlos verwendet werden. Zu den Alternativen gehört Azure AI Content material Security, das Textual content- und Bildmoderation mit anpassbaren Sicherheitsschwellenwerten und Unternehmensintegrationen unterstützt.
Häufig gestellte Fragen
A. Das neueste Moderationsmodell von OpenAI ist Omni-Moderation-neueste und unterstützt sowohl Textual content- als auch Bildmoderation.
A. Ja, OpenAI stellt Moderationsmodelle kostenlos über die Moderations-API bereit.
A. Das alte Textmoderation-latest-Modell von OpenAI unterstützt nur Texteingaben. Omni-moderation-latest wird für neue Anwendungen empfohlen.
Leidenschaftlich für Technologie und Innovation, Absolvent des Vellore Institute of Know-how. Derzeit arbeite ich als Knowledge Science Trainee mit Schwerpunkt auf Knowledge Science. Großes Interesse an Deep Studying und generativer KI, begierig darauf, modernste Techniken zur Lösung komplexer Probleme und zur Entwicklung wirkungsvoller Lösungen zu erforschen.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.