Vor ein oder zwei Jahren fühlte sich die Verwendung fortschrittlicher KI-Modelle so teuer an, dass man zweimal darüber nachdenken musste, bevor man etwas fragte. Heutzutage fühlt sich die Verwendung derselben Modelle so billig an, dass Sie die Kosten nicht einmal bemerken.
Das liegt nicht nur daran, dass „die Technologie sich verbessert hat“ im vagen Sinne. Dafür gibt es bestimmte Gründe, und es kommt darauf an, wie KI-Systeme ihre Berechnungen durchführen. Das ist es, was die Leute meinen, wenn sie darüber reden Token-Ökonomie.
Token: Die Grundeinheit
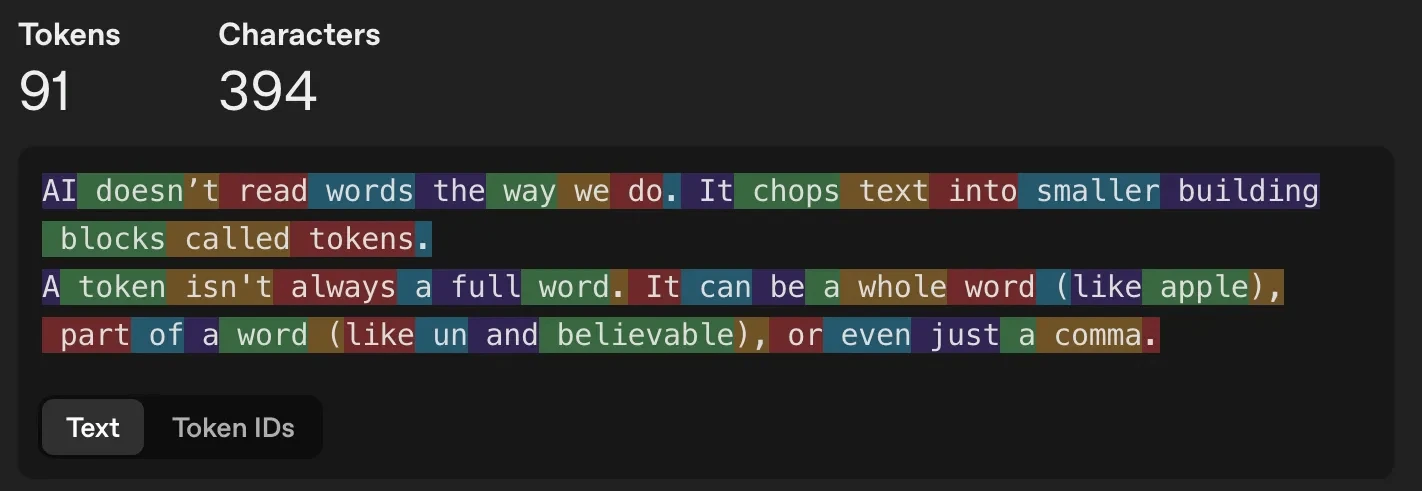
KI liest Wörter nicht so wie wir. Es zerlegt Textual content in kleinere Bausteine namens Token.
Ein Token ist nicht immer ein vollständiges Wort. Es kann ein ganzes Wort sein (wie Apfel), Teil eines Wortes (wie un Und glaubhaft) oder auch nur ein Komma.
Jeder generierte Token erfordert einen bestimmten Rechenaufwand. Wenn man additionally herauszoomt, ergeben sich die Kosten für den Einsatz von KI aus einer einfachen Beziehung:
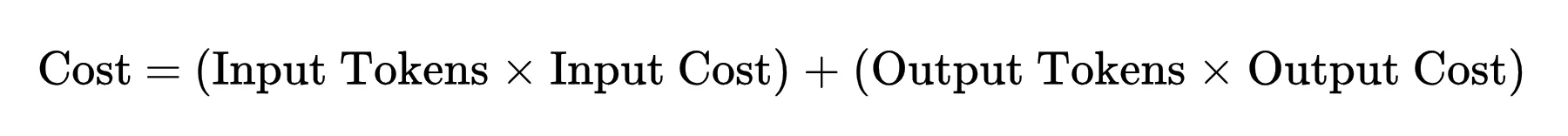
Da die Kosten für AI-Token betragen professional Million Tokendie Gleichung ergibt:
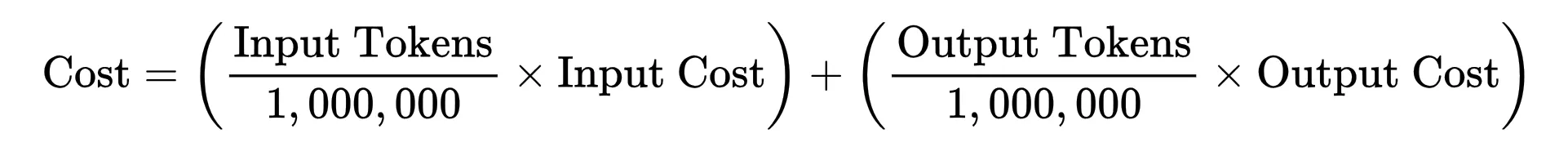
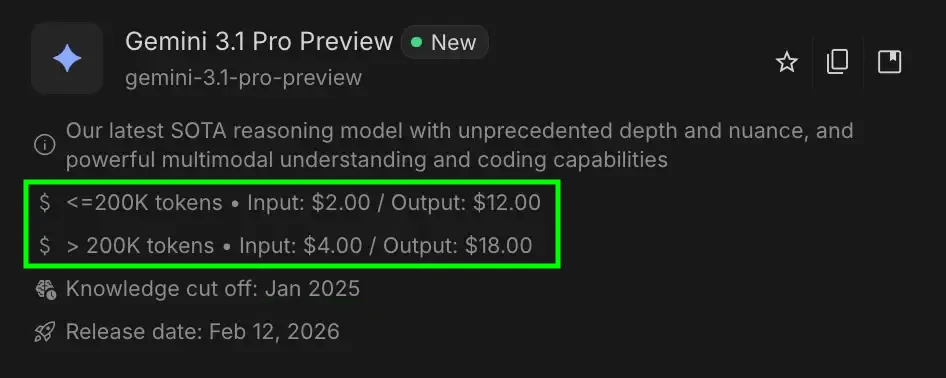
Klicken Sie hier, um zu sehen, wie die Kosten für ein Modell berechnet werden
Wir würden weiterrechnen Vorschau auf Gemini 3.1 Professional.
Nehmen wir an, Sie senden eine Eingabeaufforderung 50.000 Token (Eingabetokens) und die KI schreibt zurück 2.000 Token (Ausgabetoken).
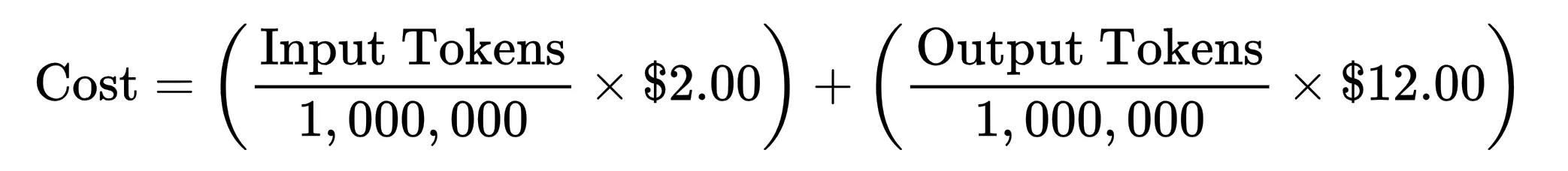
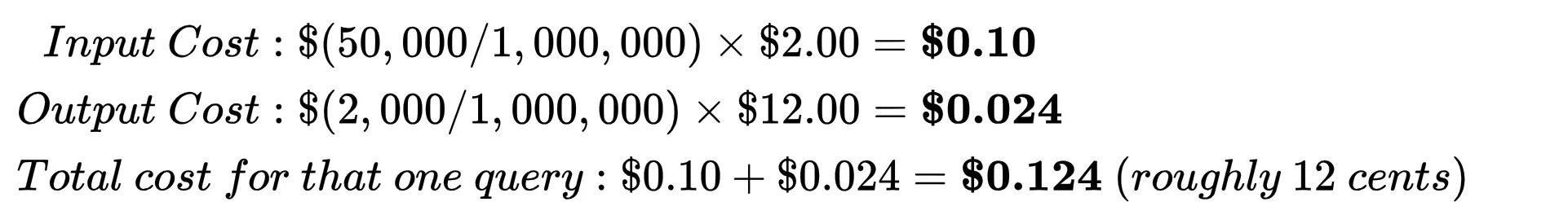
Da Token die Währung der KI sind. Wenn Sie Token kontrollieren, kontrollieren Sie auch die Kosten.
Wenn KI billiger wird, bedeutet das, dass wir eines von zwei Dingen tun:
- Reduzierung des Rechenaufwands für jeden Token (Eingabe-/Ausgabe-Tokens)
- Diese Rechenleistung günstiger machen (Token-Preis)
In Wirklichkeit haben wir es getan beide!
Weniger Rechenleistung professional Token
Die erste Welle von Verbesserungen entstand aus einer einfachen Erkenntnis:
Wir haben mehr Rechenleistung als nötig verwendet.
Frühe Modelle behandelten jede Anfrage gleich. Kleine oder große Abfragen, Textual content- oder Bildeingaben, führen Sie das vollständige Modell jedes Mal mit höchster Präzision aus. Das funktioniert, aber es ist verschwenderisch.
So wurde die Frage: Wo können wir die Rechenleistung reduzieren, ohne die Ausgabequalität zu beeinträchtigen?
Quantisierung: Jede Operation wird einfacher
Die direkteste Verbesserung kam von Quantisierung. Ursprünglich verwendeten Modelle für Berechnungen hochpräzise Zahlen. Es stellt sich jedoch heraus, dass Sie diese Präzision in den meisten Fällen erheblich reduzieren können, ohne die Leistung zu beeinträchtigen.
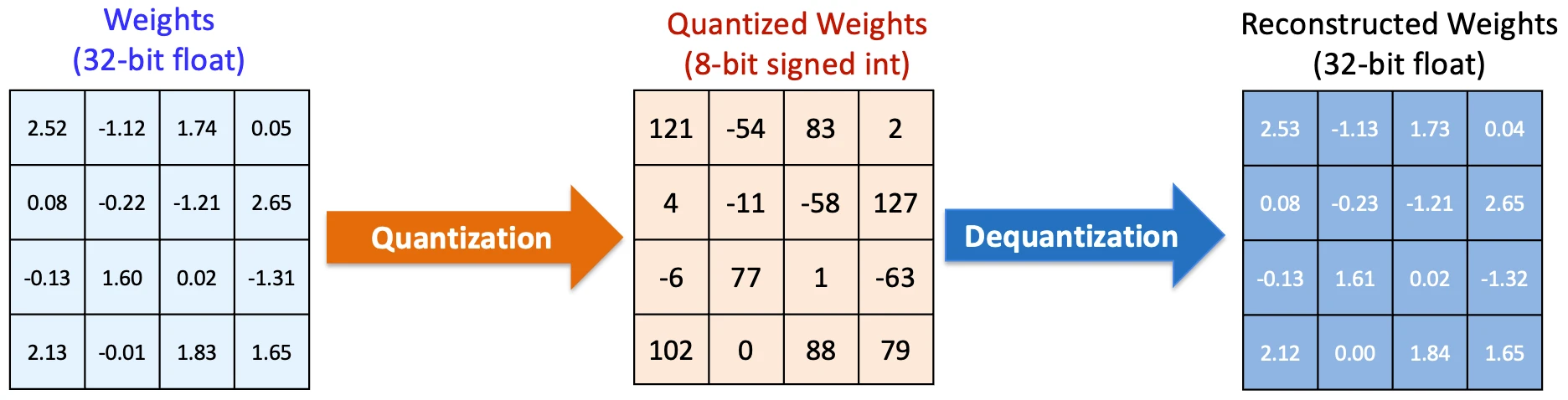
Dieser Effekt verstärkt sich schnell. Jeder Token durchläuft Tausende solcher Vorgänge, sodass bereits eine kleine Reduzierung professional Vorgang zu einer deutlichen Senkung der Kosten professional Token führt.
Notiz: Quantisierungskonstanten mit voller Genauigkeit (eine Skala und ein Nullpunkt) müssen für jeden Block gespeichert werden. Dieser Speicher ist wichtig, damit die KI die Daten später dequantisieren kann.
MoE-Architektur: Nicht jedes Mal das gesamte Modell verwenden
Die nächste Erkenntnis struggle noch einflussreicher:
Vielleicht brauchen wir nicht das gesamte Modell, um für jede Antwort zu funktionieren.
Dies führte zu Architekturen wie Expertenmischung (MoE).
Anstatt dass sich ein großes Netzwerk um alles kümmert, ist das Modell in kleinere „Experten“ aufgeteilt, von denen nur wenige für eine bestimmte Eingabe aktiviert werden. Ein Routing-Mechanismus entscheidet, welche wichtig sind.
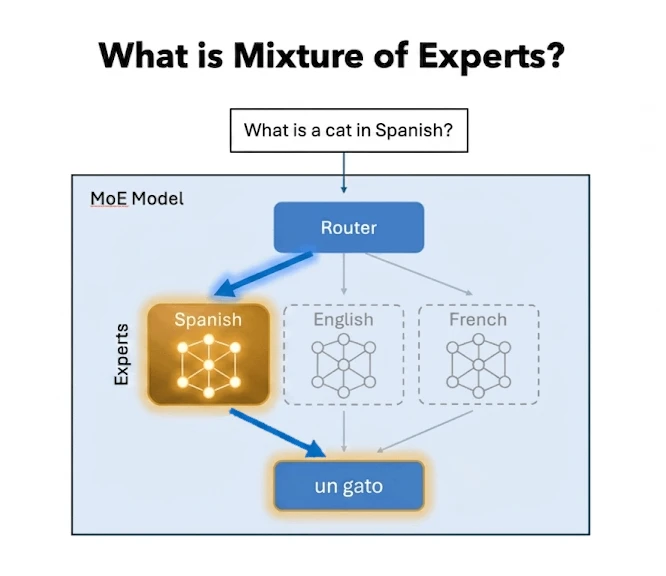
Das Modell kann additionally insgesamt immer noch groß und leistungsfähig sein, aber bei jeder Abfrage funktioniert nur ein Bruchteil davon tatsächlich.
Dies reduziert direkt die Rechenleistung professional Token, ohne die Gesamtintelligenz des Modells zu beeinträchtigen.
SLM: Die richtige Modellgröße wählen
Dann kam eine praktischere Beobachtung.
Die meisten Aufgaben in der realen Welt sind nicht so komplex. Vieles, was wir von der KI verlangen, ist repetitiv oder unkompliziert: Textual content zusammenfassen, Ausgabe formatieren, einfache Fragen beantworten.
Das ist wo Kleine Sprachmodelle (SLMs) Kommen Sie ins Spiel. Dabei handelt es sich um leichtere Modelle, die für die effiziente Bewältigung einfacherer Aufgaben entwickelt wurden. In modernen Systemen übernehmen sie häufig den Großteil der Arbeitslast, während größere Modelle schwierigeren Problemen vorbehalten sind.

Anstatt additionally ein Modell endlos zu optimieren, verwenden Sie ein viel kleineres Modell, das Ihren Zweck erfüllt.
Destillation: Komprimieren großer Modelle in kleinere
Destillation Dabei wird ein großes Modell verwendet, um ein kleineres zu trainieren und dessen Verhalten in komprimierter Type zu übertragen. Das kleinere Modell wird nicht in jedem Szenario mit dem Authentic mithalten können, für viele Aufgaben kommt es dem Authentic aber überraschend nahe.
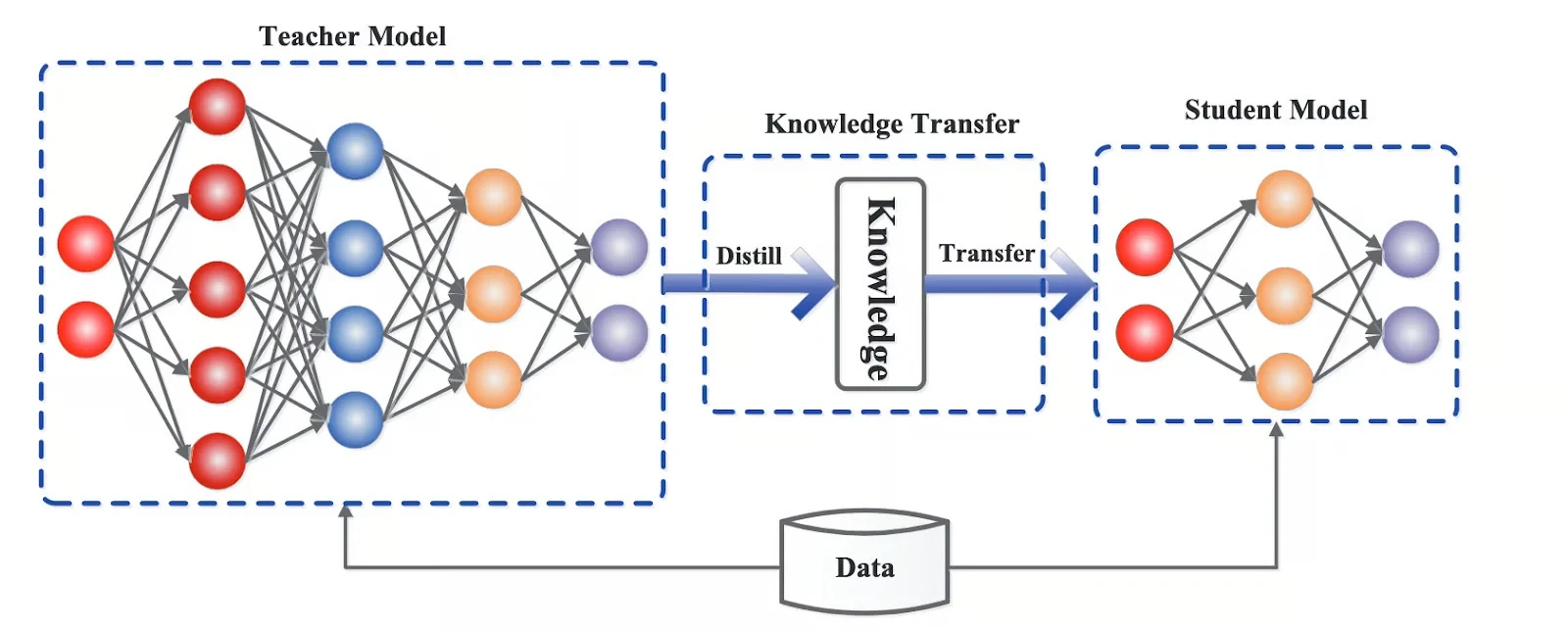
Dies bedeutet, dass Sie ein wesentlich günstigeres Modell anbieten können, während die meisten nützlichen Verhaltensweisen erhalten bleiben.
Auch hier ist das Thema dasselbe: Reduzieren Sie den Rechenaufwand professional Token.
KV-Caching: Wiederholte Arbeit vermeiden
Schließlich kommt die Erkenntnis, dass nicht jede Berechnung von Grund auf neu durchgeführt werden muss.
In realen Systemen überschneiden sich die Eingaben. Gespräche wiederholen sich. Fordert die Aktienstruktur auf.
Moderne Implementierungen machen sich dies durch Caching zunutze, bei dem Zwischenzustände aus früheren Berechnungen wiederverwendet werden. Anstatt alles neu zu berechnen, macht das Modell dort weiter, wo es aufgehört hat.
Am Modell ändert sich dadurch überhaupt nichts. Es beseitigt lediglich überflüssige Arbeit.
Notiz: Es gibt moderne Caching-Techniken wie TurboQuant was eine excessive Komprimierung in der KV-Caching-Technik bietet. Dies führt zu noch höheren Einsparungen.
Rechenleistung selbst billiger machen
Nachdem die Rechenmenge professional Token reduziert wurde, struggle der nächste Schritt offensichtlich:
Machen Sie die verbleibende Rechenleistung kostengünstiger.
Dasselbe Modell effizienter ausführen
Ein großer Fortschritt ergibt sich hier aus der Optimierung der Inferenz selbst.
Auch beim gleichen Modell kommt es darauf an, wie Sie es ausführen. Verbesserungen bei Batchverarbeitung, Speicherzugriff und Parallelisierung bedeuten, dass dieselbe Berechnung jetzt schneller und mit weniger Ressourcen durchgeführt werden kann.
In der Praxis sieht man das an Modellen wie GPT-4 Turbo oder Claude 4 Haiku. Hierbei handelt es sich um völlig neue Intelligenzebenen, die im Vergleich zu früheren Versionen schneller und kostengünstiger ausgeführt werden können.
Dies wird häufig als „optimierte“ oder „Turbo“-Variante angezeigt. Die Intelligenz hat sich nicht verändert: Die Ausführung ist lediglich präziser und effizienter geworden.
{Hardware}, die all das verstärkt
All diese Verbesserungen profitieren von {Hardware}, die für diese Artwork von Arbeitslast ausgelegt ist.
Unternehmen wie NVIDIA und Google haben Chips entwickelt, die speziell für die Arten von Operationen optimiert sind, auf die KI-Modelle angewiesen sind, insbesondere groß angelegte Matrixmultiplikationen.

Diese Chips sind besser darin:
- Umgang mit Berechnungen mit geringerer Genauigkeit (wichtig für die Quantisierung)
- Daten effizient verschieben
- viele Vorgänge parallel verarbeiten
{Hardware} allein senkt die Kosten nicht. Aber es macht jede andere Optimierung effektiver.
Alles zusammenfügen
Frühe KI-Systeme waren verschwenderisch. Jeder Token verwendete das vollständige Modell, die volle Präzision, jedes Mal.
Dann änderten sich die Dinge. Wir haben begonnen, unnötige Arbeit zu reduzieren:
- leichtere Operationen
- teilweise Modellnutzung
- kleinere Modelle für einfachere Aufgaben
- Neuberechnung vermeiden
Nachdem die Arbeitslast gesunken struggle, bestand der nächste Schritt darin, den Betrieb kostengünstiger zu gestalten:
- bessere Ausführung
- Intelligentere Dosierung
- {Hardware}, die genau für diese Vorgänge entwickelt wurde.
Deshalb sanken die Kosten schneller als erwartet.
Es gibt nicht nur einen einzelnen Faktor, der diesen Wandel auslöst. Stattdessen ist es eine stetige Verschiebung hin zu Verwenden Sie nur die Rechenleistung, die tatsächlich benötigt wird.
Häufig gestellte Fragen
A. Token sind Teile von Textual content-KI-Prozessen. Mehr Token bedeuten mehr Rechenaufwand, was sich direkt auf Kosten und Leistung auswirkt.
A. KI ist billiger, weil Systeme die Rechenleistung professional Token reduzieren und die Berechnung durch Optimierungstechniken und bessere {Hardware} effizienter machen.
A. Die KI-Kosten basieren auf Eingabe- und Ausgabe-Tokens, der Preis professional Million Tokens, wobei Nutzung und Preise professional Token kombiniert werden.
Ich bin auf die Überprüfung und Verfeinerung von KI-gestützter Forschung, technischer Dokumentation und Inhalten im Zusammenhang mit neuen KI-Technologien spezialisiert. Meine Erfahrung umfasst KI-Modelltraining, Datenanalyse und Informationsabruf und ermöglicht es mir, Inhalte zu erstellen, die sowohl technisch korrekt als auch zugänglich sind.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.