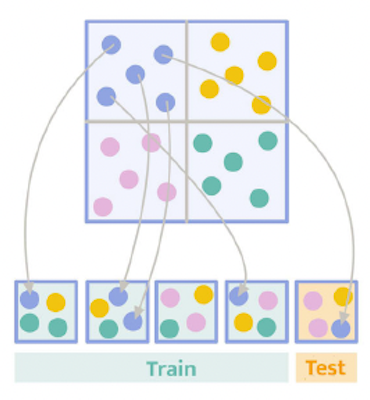
Vor drei Wochen haben wir davon erfahren Designbasierte Kreuzvalidierung (dCV)dargestellt in Abbildung 1(d) von Iparragirre et al. (2023):

Jeder Punkt ist eine PSU (primäre Stichprobeneinheit), bei der es sich um eine Einzelperson handeln kann, es sich jedoch häufig um eine Gruppe/einen Cluster von Personen handelt. Jede Farbe ist eine Schicht. dCV ist der übliche Ok-Fold-CV, aber:
- Halten Sie die Netzteile innerhalb einer Falte zusammen
- eine Spaltung ablehnen, wenn eine ganze Schicht in eine Falte fällt
- Ändern Sie die Gewichte so, dass jede Teilstichprobe die ursprüngliche Stichprobe repliziert

Kehren wir zum Drawback der Verwendung des Lebenslaufs zur Beurteilung zurück Mehrstufige Regression und Poststratifizierung (MRP) Modelle. Das haben wir gesehen Der Verlust auf individueller Ebene (y_i, yhat_i) eignet sich möglicherweise nicht für die Bewertung von MRP-Modellen, auch wenn es beschwert istund das CV-Rauschen können Modellunterschiede überdecken.
Die dCV-Methode von Iparragirre et al. (2023) ist für eine Wahrscheinlichkeitsstichprobe. MRP wird normalerweise für eine nicht wahrscheinliche Stichprobe (z. B. eine On-line-Umfrage) verwendet. Aber vielleicht gibt es hier noch etwas zu lernen.
Bayesianische Datenanalyse In Kapitel 7 über die Bewertung der Vorhersagegenauigkeit, S. 169, heißt es: „Wir können uns vorstellen, neue Daten in bestehenden Gruppen zu replizieren … oder neue Daten in neuen Gruppen.“ Neue Daten in bestehenden Gruppen ähneln Schichten, während neue Daten in neuen Gruppen Cluster-artig sind.
Iparragirre et al. (2023) sagen wir, dass Spaltung Cluster Wenn wir zwischen Coaching und Check wechseln (d. h. Nr. 1 oben nicht ausführen), wird der Fehler unterschätzt, da wir Modelle mit mehr Informationen anpassen, als wir sollten. Dies „passt“ zu den Daten. Der übliche Lebenslauf wählt additionally unnötig komplexe Modelle. (Sehen ESL Kapitel 7 zur Modellbewertung.)
Was ist mit dem Gegenteil? Schichten statt Cluster? Angenommen, wir machen Nr. 2 oben nicht und wir haben ganze Schichten innerhalb einer Falte. Dann passen wir Modelle mit weniger Informationen an, als wir sollten. Wird dies zu einer „Unteranpassung“ führen, wenn zu einfache Modelle gewählt werden?
In Mehrstufige Regression und Publishstratifizierung (MRP) Hilft es, im Lebenslauf eine Aufteilung abzulehnen, wenn eine ganze Schicht in eine Falte fällt (Nr. 2 oben)? Wenn zum Beispiel alle Mitglieder einer Alters- oder Bildungsgruppe in einen Bereich fallen, könnten wir die Aufteilung des Lebenslaufs wiederholen? Irgendwelche Referenzen, wo Leute das machen?